Использование методов разведочного анализа для оценки структуры данных с целью выбора формы и параметров нечетких решающих правил
В данном разделе развиваются и уточняются приемы и правила разведочного анализа, ориентированные на синтез нечетких решающих правил по отношению к методам, разработанным на кафедре БМИ ЮЗГУ и описанным в конце раздела 1.2.
Практически все методы разведочного анализа, ориентированные на синтез нечетких решающих правил, используют обучающие выборки, от удачного выбора которых во многом зависит качество работы синтезируемых классификаторов.В предлагаемой работе выбран способ распределения всего объема выборок из Nобъектов с известной классификацией на обучающую (N1 объект) и контрольную (N 2 объекта) в соответствии с правилом «золотого сечения» [19]. В соответствии с этим правилом объемы выборок распределяются следующим образом: N1 = 0.62*N; N2 = 0.38*N. Количество объектов Nопределяется в рамках требований к репрезентативности по статистическим критериям и/или экспертами предметной области.
Обучающие и контрольные выборки должны быть репрезентативны относительно друг друга, т.е. желательно чтобы они подчинялись одним законам распределения.
Одной из основных операций, реализуемых в ходе синтеза решающих правил, является процесс обучения, качество которого во многом определяется собираемой обучающей выборкой и составом информативных признаков.
На основании анализа терминов и различных процедур обучения процессам классификации (распознавания образов) можно сделать вывод, что на будущее качество принятия решений влияют, с одной стороны,
качественный и количественный состав обучающей выборки и, с другой стороны, качественный и количественный состав пространства информативных признаков. В свою очередь, обучающие выборки характеризуются такими показателями, как репрезентативность (принадлежность генеральной совокупности), объем и экспертное доверие. Признаковое пространство можно охарактеризовать статистическими показателями информативности, экспертным доверием к составу признаков и размерностью.
Указанные качественные и количественные показатели, характеризующие обучающие выборки и пространство признаков носят в основном эмпирический характер с явно выраженной нечеткостью определений. Исходя из этого, для описания вводимых показателей с учетом сложившейся терминологии в области нечеткой логики принятия решений и теории уверенности для обозначения целостной характеристики обучающей выборки введем понятие меры доверия к обучающим способностям выборки (МДВ), а для обозначения классификационной возможности пространства признаков - меру доверия к признаковому пространству (МДП).
Показателям МДВ и МДП придадим свойство меры доверия к принимаемым решениям Е. Шортлифа [189], определив область их изменения в диапазоне от 0 до 1, в котором нулю соответствует полное недоверие к обучающей выборке или составу информативных признаков, а единице - полное доверие к ним.
Полное доверие к обучающей выборке и составу признаков означает, что существует потенциальная возможность синтеза классификационных решающих правил, которые никогда «не ошибаются».
Аналогичным образом для обучающей выборки определим понятие меры доверия к репрезентативности выборки МДР, меры доверия к объему выборки МДО , меры доверия экспертов к выборке МДЭВ . Для пространства признаков - меры доверия к информативной ценности МДИ,
меры доверия экспертов к составу признаков МДЭП , меры доверия к размерности (количеству) информативных признаков МДК.
В зависимости от медико-технических возможностей задание и расчет выбранных показателей может осуществляться: группой
высококвалифицированных экспертов; по статистическим критериям на выборках различного, включая малого объема; с использованием смешанных стратегий (эксперты, статистические расчеты, нечеткие конструкции и операции над ними).
С учетом введенных определений оценку классификационных возможностей обучающих данных предлагается производить в соответствии со следующим методом.
1. Формируются обучающая и контрольная выборки и на экспертном уровне определяется состав показателей
МДВ = Ф1(МДР, МДО, МДЭВ)
и
МДП = Ф2(МДИ, МДЭП, МДК),
где Ф1и Ф2 - функции агрегации составляющих МДВ и МДП.
2. На экспертном уровне определяется способ расчета каждой из составляющих показателей МДВ и МДП из следующего списка: экспертное заключение, статистические оценки, смешанная стратегия.
При выборе способов оценки названных составляющих рекомендуется придерживаться следующих рекомендаций.
2.1. Если основную работу выполняют эксперты (числовая оценка мер доверия (функций принадлежности и т.д.)), то с учетом сложности решаемой задачи в соответствии с рекомендациями [111] определяется количественный состав экспертной группы и по результатам решения тестовых задач определяется согласованность ее работы с расчетом коэффициента конкордации W. Если W > 0,8 , то экспертная группа приступает к
решению поставленных задач. В противном случае состав группы качественно корректируется.
2.2. Если для расчета мер доверия используются элементы нечеткой логики принятия решений модифицированной под решение классификационных задач с применением методов разведочного анализа, то используя рекомендации работ [80, 196], обеспечивается синтез комбинированных решающих правил для расчета выбранных составляющих из следующего общего их списка:
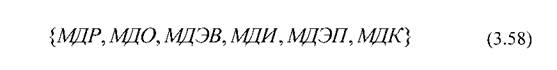
2.3. Если в ходе разведочного анализа удается установить гиперобласти пересечения Vπи объединения V0двух альтернативных классов, то формально показатель меры доверия к выборке может быть оценен выражением:

где Vπи V0- характеристики (значения функций) пересечения и объединения альтернативных классов ωpи ωr.
Показатель МДВ * может служить как для оценки МДВ , так и использоваться в составе дополнительных показателей МДР , МДО и МДЭВ с целью уточнения МДВ. Например, этот показатель может быть использован экспертами для уточнения своего мнения о величине МДЭВ.
2.4. Показатель МДО может быть определен при известном объеме обучающей выборки путем использования формулы, применяющейся для расчета объема этой выборки nдля класса ω по заданной величине
ошибки классификации или оценке вероятности правильного принятия решений. Например, используя таблицу расчета объема обучающей выборки щ в зависимости от сложности решаемой задачи Sи выбираемой оценки правильной классификации Р[94], легко решается обратная задача по расчету Р = МДО . Полагая щ известной величиной (число объектов обучающей выборки реально формируемой для решения задач обучения) и при заданной сложности решающего правила Sопределяем величину

В работе [137] описан вариант расчета объёма обучающей выборки, как зависимость вида:

где m- предварительное число возможных состояний, Wm- разность между максимальным и минимальным значениями наблюдаемых признаков, G- величина ошибки классификации, Kω- табличное значение коэффициента.
Решая обратную задачу при известной величине nv, получаем выражение для расчета Gи через него для Р = МДО:
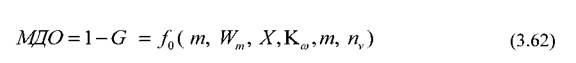
В общем виде при известных, выбираемых для конкретных задач значений nv, решая соответствующие обратные задачи, получаем статистические оценки МДО в виде зависимостей:
191

где C- множество параметров, используемых для расчета nv.
2.5. При оценке МДП для расчета показателя МДИ удобно использовать меру информативности I по Кульбаку с расчетной формулой вида:

где Imaxи Imin- максимальные и минимальные значения информативности используемого признакового пространства.
3. Учитывая различную природу показателей, используемых для оценки МДВ и МДП, а так же их различный вклад при решении различных типов задач, целесообразно для агрегации частных показателей использовать выражения вида:
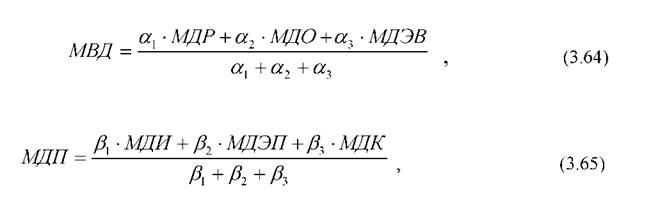
где aj , βj- весовые коэффициенты определяющие вклад частных показателей в расчет МДВ и МДП соответственно.
4. Учитывая, что составляющие МДВ и МДП дополняют друг друга в оценке классификационных возможностей используемых медицинских
данных, общую меру классификационного доверия к данным МДД будем определять выражением:
МДД= МДВ+ МДП - МДП • МДВ (3.66)
Мера доверия МДД может быть использована как для обучающих (МДД0), так и для контрольных (МДДk ) выборок.
Полученные значения мер МДД позволяют уточнять степень доверия к синтезируемым решающим правилам, т.к. учитывают не только работу самих классификационных правил, но и особенности тех данных, которые привлекаются для процессов обучения и контроля работы автоматизированной системы классификации.
Сформированные обучающие выборки могут быть использованы для проведения разведочного анализа, одной из задач которых является обеспечение структурно обоснованного выбора базовых переменных и характеристик функций принадлежности.
Рисунок 3.13 иллюстрирует вариант выбора базовой переменной функции принадлежности для случая линейно-разделимых классов ω1и o,)2 в двумерном пространстве признаков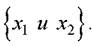 Из этого рисунка хорошо
Из этого рисунка хорошо
видно, что признаковые гистограммы классов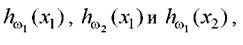 hω2(∙X2) сильно перекрываются. Так же сильно перекрываются и частные функции принадлежности, если для их построения ориентироваться на признаковые гистограммы
hω2(∙X2) сильно перекрываются. Так же сильно перекрываются и частные функции принадлежности, если для их построения ориентироваться на признаковые гистограммы
Анализ признаковых функций принадлежности показывает, что по ним нельзя построить надежных решающих правил для классификации ω1и (ι')2.
С другой стороны, имея по данным разведочного анализа информацию о линейной разделимости классов ω1и ω2, легко получить разделяющую193

построение надежного классификационного правила типа:

Рисунок 3.13 - Построение признаковых и дистальных гистограмм для
линейно-разделимых классов
В соответствии с этим правилом объект с номером j относится к тому из классов о>1 или ω2, для которого функция принадлежности максимальна.
Механизм построения функций принадлежности относительно линейной разделяющей поверхности подробно рассмотрен в разделе 3.4.
Если в ходе разведочного анализа выясняется, что в исходном многомерном пространстве один из классов ω1 является «вложенной» структурой по отношению к классу ω2, то целесообразно в качестве дистальной шкалы для гистограммы и базовой переменной для функции принадлежности использовать расстояние от центральной области «охватываемого» класса до точек обучающей выборки. Это вариант построения правила типа (3.67) иллюстрируется рисунком 3.14.
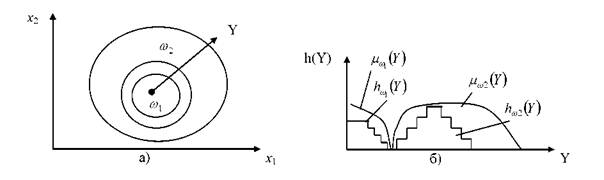
Рисунок 3.14 - Вариант выбора функций принадлежности для «вложенной» структуры классов
В разделе 3.4 было показано целесообразность использования дистальных гистограмм при решении задач определения структуры исследуемых классов с одновременной оценкой вида и параметров функций принадлежности [63, 72].
Механизм построения признаковых гистограмм достаточно подробно описан в известной литературе, механизм построения дистальных гистограмм для шкал типа: 
195

описан в разделе 3.4 и в работах [63, 64, 71].
В разделе 3.4 показан механизм построения линейной разделяющей поверхности, в результате реализации которого взаимное расположение гистограмм исследуемых пар классов дает информацию о линейной разделимости двух классов (случай не пересекающихся гистограмм hωи hωна шкале Y).
Проведенные исследования показывают, что гораздо целесообразнее использовать механизмы анализа группировок объектов, которые обладают определенной структурной целостностью и далее строить решающие правила относительно других группировок. Удобным инструментом выделения этих группировок могут служить признаковые и дистальные гистограммы при их совместном использовании, которые в дальнейшем могут составить основу для построения частных и агрегированных четких и нечетких решающих правил.
Рисунок 3.15 иллюстрирует вариант совместного использования признаковых (ПГ) и дистальных (ДГ) гистограмм на шкалах, определяемых выражениями (3.68) и (3.69), для линейно неразделимых, но непересекающихся классов.
В соответствии с рекомендациями второй главы на первом этапе разведочного анализа на шкале (3.68) строятся две пересекающиеся дистальные гистограммы hω (Y) и hω (Y).
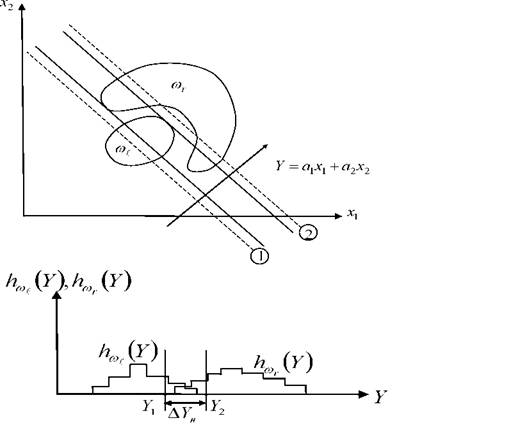
Рисунок 3.15 - Вариант исследования структуры классов с использованием шкалы типа (3.68)
На выбранном примере существует зона ΔYhнеуверенной (ненадежной) классификации ΔYh. Рекомендуется эту зону расширить, поскольку обучающая выборка имеет ограниченный характер, а реальные объекты могут располагаться за объёмом, занимаемым обучающей выборкой, (фактор DE, раздел 3.4).
За пределами интервала ΔYhклассы ωeи ωrне пересекаются и поэтому можно построить ЛРП надежно разделяющие исследуемые классы.
На втором шаге разведочного анализа с использованием подпрограмм восстановления координат исходных данных определяются координаты объектов, формирующих зону пересечения ΔYh. Из выбранных этой программой ωeи ωrмногомерных объектов создаются два подмножества классов ωtи ωr. По этим подмножествам проводится анализ структурных
данных с целью оценки их разделимости или пересечения в исходном пространстве признаков.
В ходе этого анализа по подмножествам классов ωl,и ωrстроятся признаковые гистограммы (рисунок 3.16).
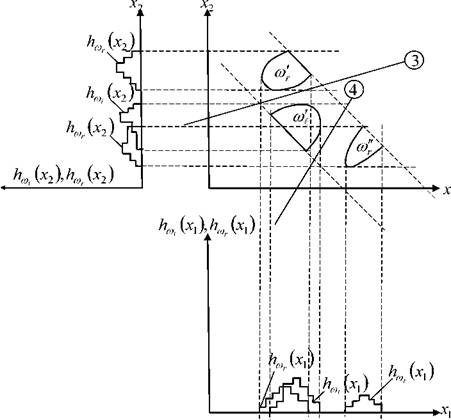
1
Рисунок 3.16 - Процесс выделения подмассивов классов ω, ωr
Анализ этих гистограмм показывает, что для примера, приведённого на рисунке 3.16, в исходном пространстве имеются две непересекающиеся области класса ωr ( ωr' и ωr" ). Если продолжить процедуру выделения объектов выбранных областей в дополнительные подмассивы ωr' и ωr" и для них строить ПГ совместно с объектами класса ω^ , то по признаку x1 наблюдается полное разделение подмассивов ω^ и ωr, а по признаку x2- подмассивов ω∣и ωr. Таким образом устанавливается факт отсутствия
пересечений классов ωiи ωrв исходном признаковом пространстве. На
следующем шаге разведочного анализа для групп объектов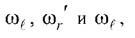
ωстроятся разделяющие плоскости «3» и «4», которые с разделяющими поверхностями «1» и «2» (рисунок 3.15) образуют кусочно-линейную разделяющую поверхность (смотри раздел 3.4).
Аналогичное наличие непересекающихся группировок может быть исследовано с использованием ДГ, строящихся на шкале типа 3.69 (рисунк 3.17).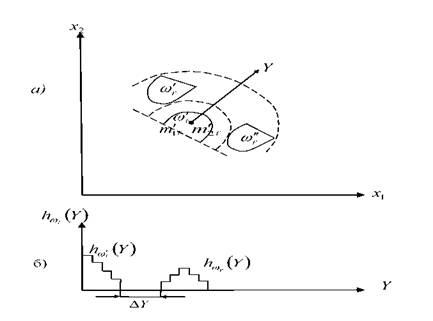
Рисунок 3.17- Иллюстрация анализа структурных данных с помощью дистальных гистограмм по шкале типа (3.69):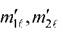 координаты «центра
координаты «центра
тяжести» объектов класса
Анализ ДГ рисунка 3.17,б показывает, что выбранные объекты класса ωrокружают объекты противоположного класса , но не пересекаются с ним.
Рисунок 3.18 иллюстрирует вариант пересекающихся классов ω1и ω2 в двумерном пространстве признаков {x1,x2}с ДГ на шкале (3.69).
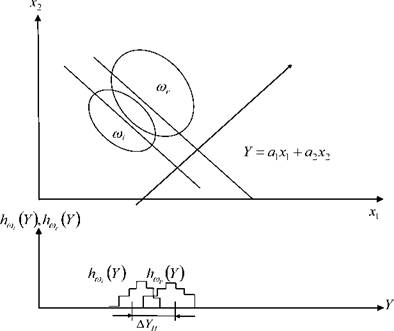
Рисунок 3.18 - Вариант пересекающейся структуры классов с ДГ
В варианте, приведённом на рисунке 3.18, признаковые и рассмотренные ранее типы ДГ не позволяют сделать вывода о структуре группировок объектов, относящихся к различным классам состояний.
Обобщив различные варианты оценки структуры данных для пересекающихся и некомпактных классов нами был разработан метод анализа структуры многомерных данных, состоящих из следующих основных этапов:
1. Обучающая выборка разбиваются на два класса: исследуемый класс ( и все остальные классы - ωr, которые составляют две ТЭД. Полученные данные определим как массивы данных первого уровня (МУ1).
2. В ходе разведочного анализа, проведённого с помощью соответствующих подпрограмм эксперты выбирают предпочтительный тип дистальных гистограмм в соответствии со следующими практическими рекомендациями:
- при наличии небольших зон пересечения признаковых гистограмм исследуемых классов (не более 20%) рекомендуется уточнить возможность
использования линейных разделяющих поверхностей с использованием шкалы типа 3.68 помощью алгоритма, предложенного в разделе 3.4.
- при большой зоне пересечения классов на ПГ, но при наличии значительных расстояний между центрами альтернативных классов (более чем четырёхкратное превышение средних расстояний между внутриклассовыми объектами), рекомендуется проверить линейную разделимость классов с использованием шкалы типа 3.68 для коэффициентов ai, уточняемых алгоритмом раздела 3.4 и далее (при необходимости) оценить возможности кусочно-линейной разделимости по алгоритму, описанному в разделе 3.4.
- в ситуации, когда на ПГ наблюдаются значительные пересечения классов, а расстояния между центрами альтернативных классов соизмеримы со средними внутриклассовыми расстояниями, целесообразно проверить гипотезу о «вложенной структуре классов» на ДГ, построенными на шкале типа 3.69.
3. С учетом структуры исследуемых классов определяется тип базовой, на которой строятся графики дистальных гистограмм.
В случае, если у экспертов возникают затруднения в выборе типа шкал для построения ДГ, то экспертам предлагается для различных типов шкал выбрать шкалу S, обеспечивающую минимальное пересечение площадей ДГ hω(S) и hω (S) . Шкалы ДГ, строящиеся для всех объектов обучающей выборки, как базовые шкалы (БШ) или шкалы первого уровня (ШПУ), а соответствующие им гистограммы - базовыми гистограммами (БГ) или гистограммами первого уровня (ГПУ). Разделяющие поверхности между альтернативными классами ω^ и ωr, строящиеся относительно БШ, определим как базовые разделяющие поверхности (БРП) или разделяющие поверхности первого уровня (РППУ).
4. На базовой шкале S определим зоны уверенной классификации (ЗУК) для классов ω и ωr- ΔSω^ и ΔSωr, а так же зону неуверенной
классификации (ЗНК) - ΔSh, определяемую по границам пересечения базовых ДГ с учетом меры (фактора) доверия к обучающей выборке (DE).
Используя подпрограмму восстановления многомерных данных определяется список объектов исходного признакового пространства, отображающиеся на интервал ΔS. Из этих объектов два новых массива для исследуемых классов ωeи ωr.
Эти массивы определим как массивы второго уровня (МУ 2).
Геометрические объекты МУ2 располагаются между двумя разделяющими гиперповерхностями, форма которой зависит от типа выбранной шкалы, а пространственное расположение параметрами уравнения разделяющей поверхности.
Например, для шкалы 3.68 это две параллельные гиперплоскости с коэффициентами {a1,..., an} (рисунок 3.18). Для шкалы 3.69 - это область между двумя гиперсферами с центром М = (m1, m2, ..., mn) и радиусами, определяемыми ΔY(рисунок 3.19).
5. Для массива МУ2разделимость классов ω , ωrисследуется аналогично п.2 и п.З. При наличии разделимости устанавливается хотя бы для некоторой группировки объектов класса ω^ полученная шкала и её ДГ сохраняется для дальнейшего анализа структуры и синтеза соответствующих решающих правил. Вторая, принятая для дальнейшего синтеза ДГ, определяется как дистальная гистограмма второго уровня, а соответствующие ей шкалы и разделяющие поверхности определяются как шкалы и разделяющие поверхности второго уровня.
6. По шкале второго уровня определяются зоны неуверенной и уверенной классификации, по которым решаются задачи структуры классов и их зон пересечения по п.п. 4 и 5 с получением шкал третьего, четвертого, пятого и т.д. уровней.
5. Процедуры п.п. 4, 5, 6 продолжаются до исчерпания групп, обеспечивающих надежную классификацию.
6. Эксперты оценивают представительность анализируемых групп объектов и решают вопрос об их включении в зону неуверенной классификации с выбором формы и расчётов параметров соответствующих функций принадлежности.
7. После синтеза решающих правил по непересекающимся областям исследуется структура зон их пересечения (при их наличии).
Эту задачу можно решать, используя систему ДГ со шкалами типа (3.69).Выбор координат rn,iдля этого шкал рекомендуются координаты всех объектов соответствующих зон неуверенной классификации для шкал любых уровней. Определим такие гистограммы как объектно-ориентированные (ООГ).
Анализ ООГ позволяет оценить близость объектов альтернативных классов с оценкой наличия зон пересечения в исходном пространстве признаков и определением объектов, выделяемых в автономные группы с надёжной классификацией.
Рисунок 3.19 иллюстрирует возможность ООГ по оценке структуры исследуемых классов. На этом рисунке представлен вариант для шкалы первого уровня, определяемой выражением 3.68.
Зона неопределенной классификации аналогична структуре классов, показанной на рисунке 3.18.Выделенные линиями массивы второго уровня на рисунке 3.19 представлены точками двумерного пространства признаков.
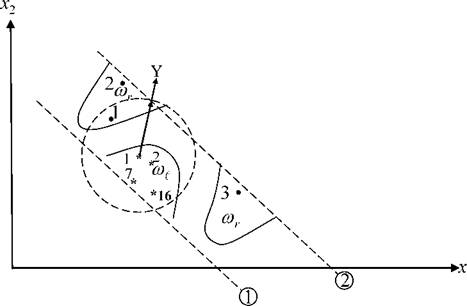
Рисунок 3.19 - Вариант распределения объектов массивов второго уровня в двумерном пространстве
На рисунке 3.19 с целью его упрощения показаны только те объекты, относительно которых далее приводятся примеры графиков ООГ (рисунок 3.30).
На рисунке 3.30 видно, что среди объектов массива второго уровня класса существуют такие, вокруг которых группируются объекты «своего» класса при достаточном удалении от них объектов «чужого» класса. Например, вокруг точки с номером 7 класса сгруппированы все объекты «своего» класса, не пересекающиеся с объектами класса ωr. Такое взаиморасположение объектов позволяет делать вывод о том, что исследуемые классы не пересекаются и целесообразно синтезировать кусочно-линейные (раздел 3.4) или эталонные (раздел 3.4) решающие правила.
204
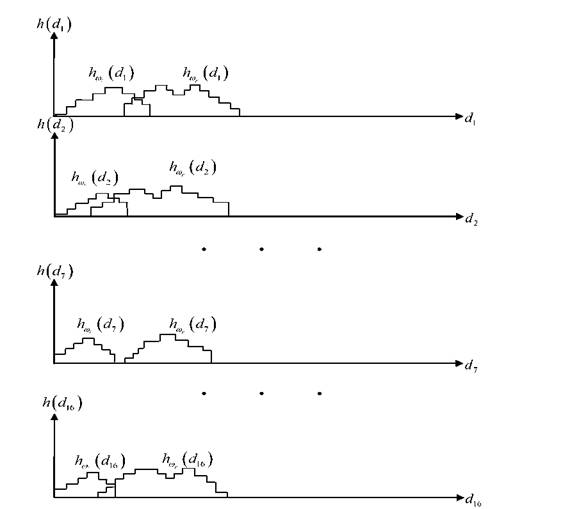
Рисунок 3.20 - Объектно-ориентированные дистальные гистограммы относительно объектов второго уровня класса : dij- расстояние от точки с номером j до остальных точек массива второго уровня
10. При осторожном отношении экспертов к обучающей выбирается способ расширения границ классов отношено гиперобъемов, в которых размещаются объекты обучающей выборки второго уровня с определением границ надежной классификации.
Координату новой границы dГ на ООГ целесообразно определять по левой границе класса ωr- d.ιr(рисунок 3.21).
205
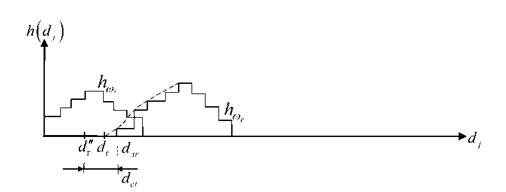
Рисунок 3.21 - Иллюстрация формирования границы надежной классификации
В зависимости от предпочтений экспертов предлагается несколько способов:
- координата drопределяется координатой точки пересечения линии соединяющей «верхние уступы» гистограммы—со шкалой dj;
- координата dFопределяется с использованием дополнительных
объектов класса ωrблизким к координатам объектов класса ;
- по среднему расстоянию между объектами исходной обучающей
выборки для класса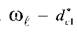 и по разности
и по разности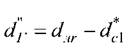 (рисунок 3.22),
(рисунок 3.22),
где n > 1 , коэффициент, определяемый экспертами, учитывающий возможность появления объектов класса ωrв окрестностях объектов класса
(рекомендуется n = 2).
- по среднему расстоянию между объектами массива второго уровня
класса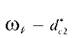 и разности
и разности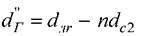
- вычислять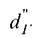 аналогично двум предыдущим способам, но по отношению к объектам класса ωr.
аналогично двум предыдущим способам, но по отношению к объектам класса ωr.
Объекты массива второго уровня класса отображающуюся на dj слева от dr, рекомендуется относить к объектам надежной классификации, с определением частного решающего правила.
Если по объектам массива второго уровня класса нет не пересекающихся гистограмм, то в исходном пространстве признаков имеется зона пересечения исследуемых классов. При полном доверии к обучающей выборке область пересечения определяется по ООГ массива второго уровня класса с минимальным пересечением гистограмм. При этом следует обратить внимание на два возможных варианта.
1. Все объекты массивов второго уровня относятся к области пересечения.
2. Выделяются область пересечения и область надежной классификации, которая при полном доверии к обучающей выборке определяется по левой границе ООГ класса ωrс решающим правилом типа:
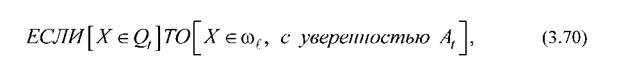
где Qt-область надежной классификации определяемая, например, неравенством типа: 
Объекты массивов второго уровня одного класса, могут сформировать несколько областей надежной классификации, например так, как это показано на рисунке 3.22.
11. После выделения зон надежной классификации на втором уровне, создаются обучающие массивы третьего уровня путем исключения из обучающей выборки объектов, вошедших в область надежной классификации. Далее выполняется пункт 10 с повторением.
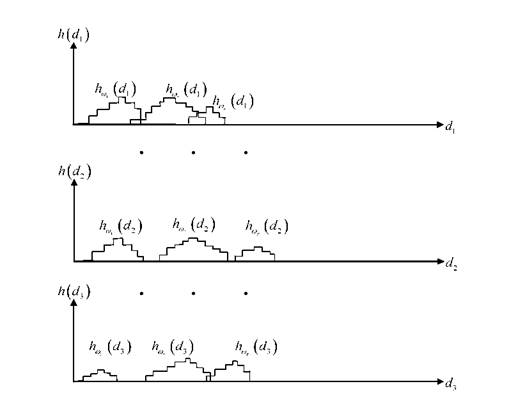
Рисунок 3.22 - Система объектно-ориентированных гистограмм относительно объектов МУ2 класса
12. При наличии областей пересечения исследуемых классов состояний определяются функции принадлежности по правилам, описанным в разделе [11].
13. При необходимости построения решающих правил для альтернативного класса процедуры разведочного анализа и синтеза нечетких решающих правил повторяются относительно вновь выбранного класса.
3.8
Еще по теме Использование методов разведочного анализа для оценки структуры данных с целью выбора формы и параметров нечетких решающих правил:
- 2.2. Метод синтеза нечетких решающих правил прогнозирования и ранней диагностики работников агропромышленного комплекса, контактирующих с ядохимикатами.
- Метод синтеза гибридных нечетких решающих правил прогнозирования возникновения и развития гангрены нижних конечностей
- Обоснование подхода к синтезу нечетких гибридных решающих правил
- Метод построения гибридных решающих правил для прогнозирования риска артериальной гипертензии
- Синтез гибридных нечетких решающих правил принятия решений на основе логики Л. Заде и Е. Шотрлифа
- Использование многомерного разведочного анализа для определения прогностической значимости клинико-морфологических факторов и полиморфизмов гена TYMS
- Синтез нечетких решающих правил прогнозирования и ранней диагностики заболеваний нервной системы.
- Синтез нечетких решающих правил прогнозирования и ранней диагностики заболеваний иммунной системы.
- Методология синтеза коллективов решающих правил для оценки и управления состоянием живых систем на основе технологий мягких вычислений
- 3.2. Синтез гибридных нечетких решающих правил прогнозирования возникновения профессиональных заболеваний работников агропромышленного комплекса, занятых в растениеводстве.
- Синтез правил нечеткого вывода с использованием теории измерения латентных переменных
- 3.5 Синтез нечетких правил принятия решений на основе идеологии метода групповые учета аргументов
- 5.2. Выбор метода и средств для лабораторного анализа
- Выбор базовых структур анализаторов данных интеллектуальных агентов нижнего иерархического уровня
- Критерии выбора параметров лазерного излучения для лечебных целей
- Нечеткие логические модули для построения базовых структур автономных агентов
- Оценка качества данных, полученных при заполнении родительской формы русской версии опросника PedsQL (2-4)
- Обзор математических методов прогнозирования, особенности использования нечеткой логики принятия решений при мочекаменной болезни
- РАЗРАБОТКА УГРОЗОМЕТРИЧЕСКОЙ СИСТЕМЫ С ИСПОЛЬЗОВАНИЕМ КОМПЛЕКСА ПРОГРАММ ПОСТРОЕНИЯ ЛИНЕЙНЫХ РЕШАЮЩИХ ПРАВИЛ НА ОСНОВЕ ПАТОМЕТРИЧЕСКОГО АЛГОРИТМА
- Алгоритм статистического тестирования прогностических решающих правил