Обоснование подхода к синтезу нечетких гибридных решающих правил
Синтез решающих правил, основанных на технологии мягких вычислений не является тривиальной задачей. Одной из основных проблем является выбор типов решающих правил адекватных структуре данных, характеризующих исследуемые состояния сложных систем.
Кроме этого в технологии мягких вычислений часто задействуются эксперты внося определенную долю субъективности, что может снижать потенциально допустимое качество принимаемых решений.С целью повышения эффективности использования технологии мягких вычислений было организовано изучение структуры данных, описывающих различные типы систем в биологии, медицине, экологии и социологии.
Изучались: типы шкал, информативность и взаимосвязь признаков, описывающих состояния исследуемых систем; геометрическая структура, динамичность, области пересечений, казуистические ситуации и другие особенности исследуемых классов состояний.
Для различных структур данных исследовалась эффективность применения различных методов, ориентированных на работу с плохоформализуемыми данными.
При этом учитывалось сложность и время синтеза решающих правил, точность получаемых результатов, требуемые затраты (время, стоимость, допустимость) на получение требуемого набора информативных признаков.
В ходе проведенных исследований было установлено, что в условиях плохой формализации при сложной структуре данных и в отсутствии репрезентативного статистического материала хороших результатов удается достичь при использовании нечеткой логики принятия решений, диалоговых систем распознавания образов, метода группового учета аргументов, теории измерения латентных переменных и последовательной секвелизационной процедуры А. Вальда [115, 169].
Кроме того было установлено, что ряд задач со сложной неоднородной структурой данных целесообразно решать используя различные модели описания различных классов состояний и (или) различных блоков информативных признаков для одной и той же сложной системы.
Таким образом, ряд практических задач по оценке состояния сложных систем требует для своего решения коллектива разнородных (гетерогенных) моделей для объединения которых в единое решающее правило необходимо разработать: механизмы изучения структуры данных; рекомендации по выбору адекватных этой структуре математических моделей и механизмы агрегации разнородных моделей в рамках технологии мягких вычислений [63, 64, 72].
Для проведения разведочного анализа ориентированного на технологию мягких вычислений может быть использован пакет прикладных программ разработанный на кафедре БМИ ЮЗГУ [140].
Анализ различных структур данных с учетом квалификации экспертных групп позволил сформировать ряд рекомендаций по выбору типов математических моделей для решения задач оценки состояния сложных систем.
1. В условиях наличия обучающей выборки, когда имеются затруднения в выборе функций принадлежности к исследуемым классам состояний, целесообразно проверить возможность использования последовательной секвенциональной процедуры А. Вальда с расчетом диагностического коэффициента ДК [115]. При переходе к нечеткому
Вальдовскому классификатору уверенность в классификации ωr= UGVr определяется функцией принадлежности к ωrс базовой переменной, определяемой по шкале ДК, то есть

11ри решении задач управления базовая переменная (3.1) UGVrможет быть использована как один из управляющих параметров.
2. Если в ходе проведения разведочного анализа по изучению структуры данных с применением отображающих пространств находятся двумерные пространства с приемлемым разделением классов в отображающем пространстве, то удобно использовать метод диалогового конструирования двумерных классификационных пространств [62, 64, 65, 82]. В соответствии с этим методом, двумерное отображающее пространство Ф = γ ? Yопределяется как декартово произведение двух отображающих функций вида:
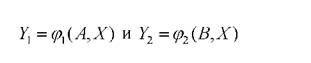
где (φи φ2- функции отображения многомерных объектов в двумерное пространство Ф;
Aи B- вектора настраиваемых параметров;
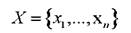 - вектора объектов многомерного пространства информативных признаков.
- вектора объектов многомерного пространства информативных признаков.
На объектах обучающей выборки в пространстве Ф в полуавтоматическом режиме, с привлечением экспертов предметной области, формируются границы разделения альтернативных классов ωsи ωrиз
условий минимального количества ошибок классификаций в виде уравнении
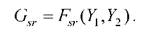
При переходе к нечеткой классификации в двумерном отображающем пространстве четкий вывод метода диалогового конструирования двумерных классификационных пространств трансформируется в нечеткое решение путем определения функций принадлежности μω (Dr) к классу ωrс базовой переменной, определяемой как расстояние Drот отображения в Ф исследуемого объекта до двумерных границ класса ωrописываемых уравнением вида Gr= Fr (Y1,Y2).
Уверенность в ω, полученную при диалоговом конструировании двумерных классификационных пространств определим соотношением:

В задачах управления двумерное отображающее пространство позволяет наблюдать эффект от управляющих воздействий и прогнозировать переход объекта из одного класса состояний в другое как при естественных так, и при искусственных (этап моделирования) управляющих воздействиях.
3. Если в ходе проведения разведочного анализа выясняется возможность построения разделяющих поверхностей между классами и (или) формирования некоторых электронных структур (точки, гиперсферы, гиперпараллелепипеды и т.д.), то используя классические методы теории распознавания образов, осуществляется синтез разделяющих поверхностей и (или) эталонных структур. Переход к нечетким классификаторам осуществляется через функции принадлежности μω (Dkr) с базовыми переменными по расстояниям Dдо разделяющих поверхностей и (или) эталонных структур с номерами к.
Уверенность в принимаемых решениях определяется по максимальным значениям соответствующих функций принадлежности [68,69]:120

В задачах управления переменная UGVrможет использоваться как управляющий параметр.
4. Если, в условиях п.3 выясняется целесообразность нечеткой
аппроксимации многомерных областей нечеткими многомерными гиперпараллелепипедами, то, каждый из гиперпараллелепипедов определяется выражением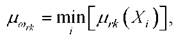 где k- номер нечеткого
где k- номер нечеткого
гиперпараллелепипеда в многомерном пространстве признаков. Множество, аппроксимирующих гиперпараллелепипедов для класса ωr, объединяется выражением:

Задача управления определяется как задача перевода из текущих в искомый гиперпараллепипед.
5. Если, в условиях отсутствия обучающих выборок, врачи-
эксперты способны строить функции принадлежности к исследуемым классам заболеваний, то рекомендуется использовать классический аппарат нечеткой логики принятия решений, в котором в качестве базовых элементов используются функции принадлежности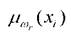 и (или)
и (или)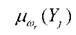 к
к
исследуемым классам состояний ωс базовыми переменными, определяемыми по шкалам информативных признаков х и (или) комплексных показателей Y., вычисляемых по информативным показателям
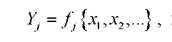 где fфункциональная зависимость, «связывающая» все или часть информативных признаков с Y[63, 64]:
где fфункциональная зависимость, «связывающая» все или часть информативных признаков с Y[63, 64]:
Наиболее популярными формулами агрегации при использовании функций принадлежностей являются выражения вида:
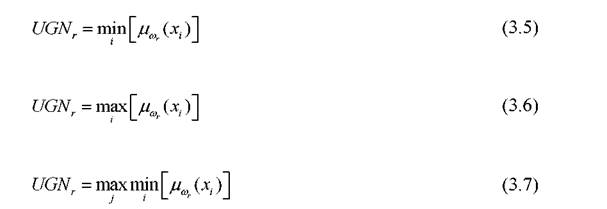
При известных функциях принадлежности задача управления решается с использованием нечетких алгоритмов Заде, такоги-сугена-конга, нечетких нейронных сетей.
6.
Если в условиях отсутствия обучающих выборок клиницисты способны выбрать систему признаков, подтверждающих и (или) опровергающих гипотезы ωи для них определить условия подтверждения и (или) опровержения соответствующих гипотез, то предпочтение отдается итерационным процедурам Е. Шортлифа: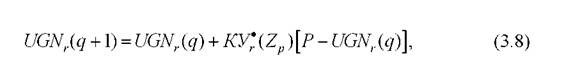
где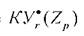 - уверенность в гипотезе ωот свидетельства (признака,
- уверенность в гипотезе ωот свидетельства (признака,
интегрального показателя) Z.
Часто уверенность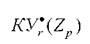 представляется как функция
представляется как функция
принадлежности к классу ωrс базовой переменной xi.
В задачах управления величину UGVудобно использовать в качестве управляющего параметра с предсказанием уверенности перехода в «желаемые» классы (класс) состояний.
7. Метод группового учения аргументов (МГУА) характеризуется использованием моделей структурно параметрической идентификации представленных компонентами Колмогорова-Габора [6, 48, 49].
В ходе процесса обучения для каждого из исследуемых классов состояний ωfв пространстве информативных признаков с использованием обучающих алгоритмов МГУА получаются наборы моделей взаимосвязей между различными информативными признаками:

где x. - признак с номером j, рассчитанный по объектам обучающей выборки класса вектор группы признаков с номером к пространства
вектор группы признаков с номером к пространства
информационных признаков, причем признак с номером jне входит в группу к ; F.- функция связи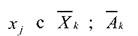 - вектор настраиваемых
- вектор настраиваемых
параметров.
Для нечеткого представления исследуемых классов состояний вводится функция принадлежности μb, (D,.) к классу ф, с базовой переменной Dtr, определяемой как расстояние от точки многомерного пространства до модели с номером rкласса ωl [6].
Уверенность в классификации при использовании нечеткого МГУА определяется выражением:

где Lколичество уравнений (2.9) в классе ωt.
Варианты использования алгоритмов МГУА в задачах управления описаны в работах [6, 48, 49].
8. В теории измерения латентных переменных реализуется положение о том, что информативные признаки, с помощью которых оценивается состояние исследуемых систем, получают путем прямого измерения либо вычисляют по результатам прямых измерений. Результат оценки состояния сложных систем (подсистем) определяется не прямыми измерениями, а в ходе анализа исходных признаков и (или) комбинированных показателей получаемых расчетным путем. Это позволяет сделать вывод о том, что теория латентных переменных является адекватной по отношению к решаемому классу задач [214].
В терминологии теории измерения латентных переменных исходные медицинские признаки и четко вычисляемые параметры определяются как индикаторные переменные, а неопределенные априори результаты - как латентные (скрытые) переменные.
Исследование роли индикаторных переменных в измерении латентных переменных удобно производить с помощью стандартного пакета, диалоговых прикладных программ RUMM 2020 (Rasch unidimensional Measurement Models). Используя значения индикаторных переменных переведенных в логиты пакет RUMM 2020, строит теоретические кривые модели Г. Раша, по которым судят о соответствии индикаторных переменных моделями Г. Раша и в ходе итерационных процедур формируют пространство информативных признаков [214].
В пакете RUMM 2020 предусмотрена возможность определения функциональной связи между латентной переменной L и выбранным набором индикаторных переменныхЛ', :

где f- вид функциональной зависимости Lот Sj.
При оценке состояния сложных систем в качестве латентной переменной могут выступать уверенность в прогнозе перехода системы из
одного состояния в другое; уверенность в том, что система находится в одном из классов состояний ωt; уверенность в эффективности выбранной схемы управления и т.д.
При переходе к принятым в работе механизмам нечеткой классификации целесообразно использовать функции принадлежностей к исследуемым классам состояний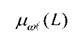 с базовой переменной L
с базовой переменной L
определяемой в логитах. Для перехода от Lк μωt (L)удобно использовать такую обобщенную характеристику, определяемую пакетом RUMM 2020, как гистограмма распределения объектов исследования на шкале латентной переменной L. При этом функции μω(L)удобно строить используя рекомендации работ [62, 63].
Таким образом, модель Г. Раша может быть использована для нечеткой оценки состояния объекта исследования с расчетом уверенности в классификации в соответствии с выражением:

В задачах управления величина UGVrможет быть использована как управляющий параметр.
В общем виде при агрегации рассмотренных решающих правил в их гибридные коллективы могут использоваться известные методы теории распознавания образов в которые показатели получаемые по формулам 2.1,...,2.12 используются как пространство информативных признаков.
При использовании технологии мягких вычислений такой синтез целесообразно производить с учетом особенностей решаемых задач.
Например, различные по своей природе группы признаков агрегируются «своими» типами решающих правил.
В другом варианте все информативные признаки обрабатываются каждым из правил входящих в коллектив. Возможен смешанный вариант,
при котором различные решающие правила используют смешанные, возможно пересекающихся, группы информативных признаков. Такие группировки могут создаваться по различному принципу: по стоимости получения информации; по времени измерения; по информативности; по особенности структуры данных и т.д.
Один из возможных методов синтеза коллектива рассмотренных выше нечетких решающих правил может быть представлен следующим образом [62, 63].
При осторожной стратегии, когда решение должно приниматься при обязательном учете «мнения» всех участков коллектива, с учетом возможных «сомнений» в направлении альтернативы (к классу ωr) целесообразно использовать агрегатор типа:
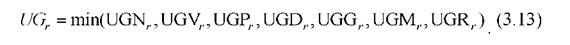
Если ставиться задача «не пропустить» объекты класса ωrили если степень доверия к каждому из решающих правил примерно одинакова, целесообразно проверить применимость (качество работы) решающего правила типа:
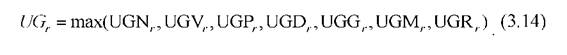
Если использование каждого из правил добавляет уверенность в принятии решений относительно гипотезы ωr, то целесообразно использовать итерационные накопительные процедуры, например, Е. Шортлифа: 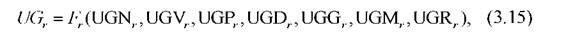
где F - накопительная итерационная функция.
При наличии репрезентативных обучающих выборок и адекватности модели Г. Раша, рассматривая результат работы агрегирующих функций как латентную переменную индикаторных функций, частных составляющих UGNr ,UGVr ,UGPr ,UGDr ,UGGr ,UGMr ,UGR rпроцедуру агрегации целесообразно производить, используя выражение вида:
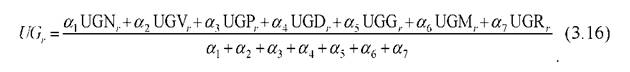
Еще по теме Обоснование подхода к синтезу нечетких гибридных решающих правил:
- Метод синтеза гибридных нечетких решающих правил прогнозирования возникновения и развития гангрены нижних конечностей
- Синтез гибридных нечетких решающих правил принятия решений на основе логики Л. Заде и Е. Шотрлифа
- 3.2. Синтез гибридных нечетких решающих правил прогнозирования возникновения профессиональных заболеваний работников агропромышленного комплекса, занятых в растениеводстве.
- Синтез нечетких решающих правил прогнозирования и ранней диагностики заболеваний нервной системы.
- 2.2. Метод синтеза нечетких решающих правил прогнозирования и ранней диагностики работников агропромышленного комплекса, контактирующих с ядохимикатами.
- Синтез нечетких решающих правил прогнозирования и ранней диагностики заболеваний иммунной системы.
- Метод построения гибридных решающих правил для прогнозирования риска артериальной гипертензии
- Использование методов разведочного анализа для оценки структуры данных с целью выбора формы и параметров нечетких решающих правил
- 3.5 Синтез нечетких правил принятия решений на основе идеологии метода групповые учета аргументов
- 3.3. Синтез гибридных нечетких моделей ранней диагностики профессиональных заболеваний работников агропромышленного комплекса, занятых в растениеводстве.
- Синтез нечетких правил принятия решений с разделяющими гиперповерхностями и многомерными эталонами
- Синтез гибридных нечетких моделей прогнозирования возникновения и рецидивов гангрены нижних конечностей
- Синтез правил нечеткого вывода с использованием теории измерения латентных переменных
- Методология синтеза коллективов решающих правил для оценки и управления состоянием живых систем на основе технологий мягких вычислений
- Алгоритм статистического тестирования прогностических решающих правил