оПНЕЙРХПНБЮМХЕ АЮГШ ГМЮМХИ ДКЪ АХНРЕУМХВЕЯЙНИ ЯХЯРЕЛШ КЕВЕМХЪ Х ДХЮЦМНЯРХЙХ ГЮАНКЕБЮМХИ КЕЦЙХУ
б МЮЯРНЪЫЕЕ БПЕЛЪ АНКЭЬХЕ НАЗЕЛШ ЛЕДХЖХМЯЙХУ ДЮММШУ ЯНАХПЮЧРЯЪ Х УПЮ╜МЪРЯЪ Б ЩКЕЙРПНММНЛ БХДЕ. уПЮМЕМХЕ ЛЕДХЖХМЯЙХУ ДЮММШУ, РЮЙХУ ЙЮЙ ОЕПЯНМЮКЭМШЕ ДЮММШЕ, РЮЙХЕ ЙЮЙ ЯМХЛЙХ ЙНЛОЭЧРЕПМНЦН РНЛНЦПЮТЮ, ЛНФЕР АШРЭ БШОНКМЕМН МЕ╜ЯЙНКЭЙХЛХ ЯОНЯНАЮЛХ.
лНФМН УПЮМХРЭ ЯМХЛЙХ йр Б БХДЕ ТЮИКНБ Б НОПЕДЕКЕММНИ ЯРПСЙРСПЕ ЙЮРЮКНЦНБ. нДМЮЙН ЩРНР РХО ПЕЬЕМХЪ МЕ ОНДУНДХР ДКЪ УПЮМЕМХЪ ЛЕДХЖХМ╜ЯЙХУ ДЮММШУ, РЮЙ ЙЮЙ ЛЕДХЖХМЯЙХЕ ДЮММШЕ РПЕАСЧР АНКЭЬЕ ЛЕРЮДЮММШУ, ОНЛХЛН ХЛЕМХ ТЮИКЮ. нАШВМН ХЯОНКЭГСЕЛШИ ЛЕРНД УПЮМЕМХЪ ДЮММШУ ЩРН АЮГ ДЮММШУ. лНФ╜МН ХГБКЕЙЮРЭ, БЯРЮБКЪРЭ ХКХ СДЮКЪРЭ ДЮММШЕ Я ХЯОНКЭГНБЮМХЕЛ ЯХЯРЕЛШ СОПЮБКЕМХЪ АЮГЮЛХ ДЮММШУ (ясад). ясад ГЮАНРХРЯЪ Н ЯНЦКЮЯНБЮММНЯРХ ДЮММШУ. хЯОНКЭГНБЮМХЕ АЮГШ ДЮММШУ ОНГБНКЪЕР АНКЕЕ ЩТТЕЙРХБМН НАЛЕМХБЮРЭЯЪ ДЮММШЛХ ЛЕФДС ХЯЯКЕДНБЮ╜РЕКЪЛХ Х / ХКХ АНКЭМХЖЮЛХ. пЕВЭ ХДЕР Н АЮГЕ ДЮММШУ, ЙНРНПЮЪ ЯНДЕПФХР ЩКЕЙРПНММШЕ ЛЕДХЖХМЯЙХЕ ДЮММШЕ, Б ЙЮВЕЯРБЕ ЛЕДХЖХМЯЙНИ АЮГШ ДЮММШУ.лЕДХЖХМЯЙХЕ АЮГШ ДЮММШУ ПЮГКХВЮЧРЯЪ ОН ПЮГЛЕПС, МЮГМЮВЕМХЧ Х ХЯОНКЭГН╜БЮМХЧ. нМХ БЮПЭХПСЧРЯЪ НР МЕАНКЭЬХУ АЮГ ДЮММШУ, ПЮЯОНКНФЕММШУ Б НРДЕКЕМХХ АНКЭМХЖШ, ЦДЕ УПЮМЪРЯЪ ДХЮЦМНГШ, ДН МЮЖХНМЮКЭМШУ ЯХЯРЕЛ ЛЕДХЖХМЯЙХУ ГЮОХЯЕИ Х БЯЕЦН, ВРН ЛЕФДС МХЛХ. мЕЙНРНПШЕ АЮГШ ДЮММШУ ЯНДЕПФЮР ХМТНПЛЮЖХЧ Н ОЮЖХЕМРЕ, РЮЙСЧ ЙЮЙ ХЛЪ ОЮЖХЕМРЮ, ДПСЦХЕ ЯНДЕПФЮР РНКЭЙН ЮМНМХЛМСЧ ХМТНПЛЮЖХЧ, ХЯОНКЭ╜ГСЕЛСЧ ДКЪ ЯРЮРХЯРХВЕЯЙХУ ЖЕКЕИ ХКХ ХЯЯКЕДНБЮМХИ.
MeDIA (ЯНЙПЮЫЕМХЕ НР Medical Data Integration Application) - МЮГБЮМХЕ ЯХЯРЕ╜ЛШ СОПЮБКЕМХЪ ЛЕДХЖХМЯЙНИ АЮГНИ ДЮММШУ, ЙНРНПЮЪ Б МЮЯРНЪЫЕЕ БПЕЛЪ ПЮГПЮАЮРШ╜БЮЕРЯЪ. яЕМЯНПМШЕ ДЮММШЕ, ЙНРНПШЕ MeDIA ЛНФЕР УПЮМХРЭ, БЙКЧВЮЧР Б ЯЕАЪ щщц,
лпр ХКХ йр БЛЕЯРЕ Я ЯННРБЕРЯРБСЧЫХЛХ ЛЕРЮДЮММШЛХ, РЮЙХЛХ ЙЮЙ ХМТНПЛЮЖХЪ Н ОЮЖХЕМРЕ Х ЮММНРЮЖХХ. нЯМНБМНЕ ОПЕХЛСЫЕЯРБН MeDIA ОЕПЕД ОПНЯРШЛ УПЮМЕМХЕЛ ДБНХВМШУ ДЮММШУ ГЮЙКЧВЮЕРЯЪ Б РНЛ, ВРН MeDIA НАПЮАЮРШБЮЕР ОПНХЯУНФДЕМХЕ, МЕ╜НОПЕДЕКЕММНЯРЭ, СОПЮБКЕМХЕ БЕПЯХЪЛХ Х ЛНФЕР ЙНЛАХМХПНБЮРЭ ПЮГКХВМШЕ РХОШ ДЮММШУ, МЮОПХЛЕП, щщц Х лпр.
йПНЛЕ РНЦН, ЙНЦДЮ ЙРН-РН УНВЕР ОПНЯЛНРПЕРЭ ДЮММШЕ щщц Х лпр НР НДМНЦН ОЮЖХЕМРЮ, НМ ЛНФЕР ГЮОПНЯХРЭ MeDIA БЛЕЯРН РНЦН, ВРНАШ ГЮ╜ОПЮЬХБЮРЭ ПЮГМШЕ АЮГШ ДЮММШУ ОН НРДЕКЭМНЯРХ. яСЫЕЯРБСЕР РПХ ТСМЙЖХХ: ОПНХЯ╜УНФДЕМХЕ, МЕНОПЕДЕКЕММНЯРЭ Х СОПЮБКЕМХЕ БЕПЯХЪЛХ, ЙНРНПШЕ НРКХВЮЧР MeDIA НР НАШВМШУ ЩКЕЙРПНММШУ ЯХЯРЕЛ ЛЕДХЖХМЯЙНИ ДНЙСЛЕМРЮЖХХ.оПНХЯУНФДЕМХЕ ХЯОНКЭГСЕРЯЪ, ВРНАШ ОНЙЮГЮРЭ, НРЙСДЮ ОПНХЯУНДХР ЙНМЙПЕРМШИ ЩКЕЛЕМР ДЮММШУ. мЮОПХЛЕП, ЕЯКХ ЕЯРЭ ЩКЕЛЕМРШ ДЮММШУ a, b, Я Х Я, НОПЕДЕКЕМШ ЙЮЙ Я = a + b, Я БШБНДХРЯЪ ХГ Ю Х b. щРН ЛНФЕР АШРЭ ХЯОНКЭГНБЮМН, МЮОПХЛЕП, Б ДХЮЦМНЯРХ╜ВЕЯЙНИ РЮАКХЖЕ. йЮФДШИ ДХЮЦМНГ ОЕПЕВХЯКЪЕР ЯЕМЯНПМШЕ ДЮММШЕ, МЮ ЙНРНПШУ НМ НЯ╜МНБЮМ. еЯКХ ОН ЙЮЙНИ-РН ОПХВХМЕ НОПЕДЕКЕММШИ МЮАНП ЯЕМЯНПМШУ ДЮММШУ ДНКФЕМ АШРЭ НРЙКНМЕМ ХГ-ГЮ МЕОПЮБХКЭМНИ ГЮОХЯХ, КЕЦЙН НОПЕДЕКХРЭ, ЙЮЙНИ ДХЮЦМНГ МЕНАУН╜ДХЛН ОЕПЕЯЛНРПЕРЭ.
мЕНОПЕДЕКЕММНЯРЭ Б АЮГЕ ДЮММШУ НГМЮВЮЕР, ВРН Й ЩКЕЛЕМРЮЛ Б АЮГЕ ДЮММШУ ОПХЙПЕОКЕМЮ НОПЕДЕКЕММЮЪ БЕПНЪРМНЯРЭ.
сОПЮБКЕМХЕ БЕПЯХЪЛХ - ЩРН БНГЛНФМНЯРЭ НРЯКЕФХБЮРЭ ОПЕДШДСЫХЕ БЕПЯХХ ЩКЕЛЕМРНБ ДЮММШУ. мЮОПХЛЕП, ОПЕДОНКНФХЛ, ВРН ЛЕДХЖХМЯЙНЕ СВПЕФДЕМХЕ УПЮМХР ХМТНПЛЮЖХЧ Н ОЮЖХЕМРЮУ Б АЮГЕ ДЮММШУ. хЯОНКЭГСЪ СОПЮБКЕМХЕ БЕПЯХЪЛХ, ЯРЮПШЕ ДЮММШЕ ЮПУХБХПСЧРЯЪ, Ю РЕЙСЫХЕ НАМНБКЪЧРЯЪ. аЮГЮ ДЮММШУ, РЮЙХЛ НАПЮГНЛ, УПЮМХР РЕЙСЫСЧ Х ЮЙРСЮКЭМСЧ ХМТНПЛЮЖХЧ Н ОЮЖХЕМРЮ, РЮЙ Х ОПЕДШДСЫХЕ ДЮММШЕ, Б РНЛ ВХЯКЕ ДЮММШЕ Н АНКЕЕ ПЮММХУ НАЯКЕДНБЮМХЪУ.
MeDIA ЯНЯРНХР ХГ МЕЯЙНКЭЙХУ ЙНЛОНМЕМРНБ, РЮЙХУ ЙЮЙ ХМРЕПТЕИЯ ОПХЙКЮДМНЦН ОПНЦПЮЛЛХЯРЮ (API) Х ЩЙЯРПЮЙРНПШ ТСМЙЖХИ. мЮ ПХЯСМЙЕ 2.4 ОНЙЮГЮМ ДХГЮИМ MeDIA. оПНЦПЮЛЛМНЕ НАЕЯОЕВЕМХЕ ОНКЭГНБЮРЕКЪ ЯБЪГШБЮЕРЯЪ Я ЯХЯРЕЛНИ ВЕПЕГ API.
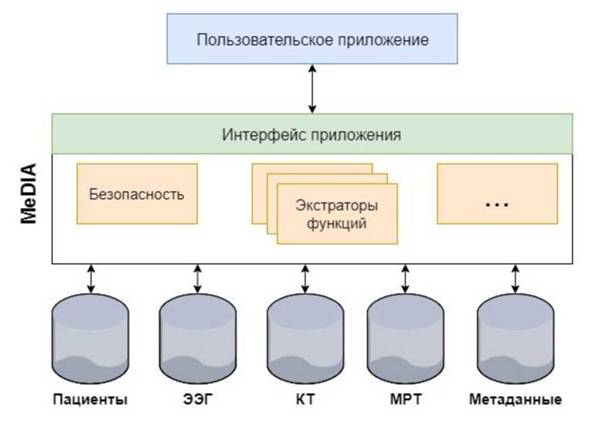
пХЯСМНЙ 2.4 - йНЛОНМЕМРШ MeDIA
MeDIA ГЮАНРХРЯЪ Н УПЮМЕМХХ ЯЕМЯНПМШУ ДЮММШУ, РЮЙХУ ЙЮЙ ГМЮВЕМХЪ щщц, ХГ╜БКЕВЕМХЕ ТСМЙЖХИ Х ОНБШЬЕМХЕ АЕГНОЮЯМНЯРХ (МЮОПХЛЕП, ЬХТПНБЮМХЕ ЙНМТХДЕМЖХ╜ЮКЭМШУ ДЮММШУ). щЙЯРПЮЙРНПШ ЩКЕЛЕМРНБ ХГБКЕЙЮЧР ЬЮАКНМШ ХКХ ЩКЕЛЕМРШ, ЙНРН╜ПШЕ ЛНЦСР, МЮОПХЛЕП, ПЮГПЕЬХРЭ НРЙКНМЕМХЕ ЮПРЕТЮЙРНБ, ХГ МЕНАПЮАНРЮММШУ ДЮМ╜МШУ.
бЯЪ ДНОНКМХРЕКЭМЮЪ ХМТНПЛЮЖХЪ, ЦЕМЕПХПСЕЛЮЪ ЙНЛОНМЕМРЮЛХ MeDIA, УПЮ╜МХРЯЪ Б АЮГЕ ДЮММШУ Meta. MeDIA API ОПЕНАПЮГСЕР ГЮОПНЯШ ОНКЭГНБЮРЕКЭЯЙНЦН ОПХ╜КНФЕМХЪ Б ГЮОПНЯШ Й ЛЕРЮДЮММШЛ Х ТЮИКЮЛ ДЮММШУ. гЮОПНЯШ Й API МЮОХЯЮМШ МЮ ЪГШЙЕ MediQL. MeDIA ОПЕНАПЮГСЕР ЩРНР ГЮОПНЯ Б ОНДГЮОПНЯЮУ Й ПЮГКХВМШЛ АЮГЮЛ ДЮММШУ, ЙНРНПШЕ ЛНЦСР АШРЭ SQL, XQuery ХКХ, Б ЯКСВЮЕ, ЙНЦДЮ ЯЕМЯНПМШЕ ДЮММШЕ УПЮМЪРЯЪ Б НАШВМШУ ТЮИКЮУ, БШГНБЮЛХ ТЮИКНБНИ ЯХЯРЕЛШ.
рНОНКНЦХЪ АЮГШ ДЮММШУ Х ПЮАНВХУ ЯРЮМЖХИ ОНЙЮГЮМЮ МЮ ПХЯСМЙЕ 2.3. аНКЭМХ╜ЖЮ ХЛЕЕР БМСРПЕММЧЧ ЯЕРЭ, ЙНРНПЮЪ НАНГМЮВЕМЮ МЮ ПХЯСМЙЕ ЯЕПШЛ ТНМНЛ. аПЮМДЛЮС╜ЩП ТХКЭРПСЕР БЕЯЭ РПЮТХЙ хМРЕПМЕРЮ. аПЮМДЛЮСЩП МЮЯРПНЕМ РЮЙХЛ НАПЮГНЛ, ВРН НМ МЕ ПЮГПЕЬЮЕР БУНДЪЫХЕ ЯНЕДХМЕМХЪ ХГ хМРЕПМЕРЮ Я АЮГНИ ДЮММШУ. оНЩРНЛС ДНЯРСО Й АЮГЕ ДЮММШУ НЦПЮМХВЕМ КЧАНИ ПЮАНВЕИ ЯРЮМЖХЕИ Б ЯЕРХ АНКЭМХЖШ. щРН ЛНФЕР ЯВХ╜РЮРЭЯЪ УНПНЬЕИ ОПЮЙРХЙНИ, ОНЯЙНКЭЙС ЩРН ЛНФЕР ЯЛЪЦВХРЭ МЕЙНРНПШЕ ЮРЮЙХ ЯН ЯРН╜ПНМШ СГКНБ БМЕ ЯЕРХ, МЮОПХЛЕП, ОПХ ЮРЮЙЕ МЮ СЪГБХЛНЕ ОПНЦПЮЛЛМНЕ НАЕЯОЕВЕМХЕ, ПЮАНРЮЧЫЕЕ МЮ ЯЕПБЕПЮУ АНКЭМХЖШ. нДМЮЙН, ОНЯЙНКЭЙС Б ЯЮЛНИ АНКЭМХВМНИ ЯЕРХ ЛМНЦН ЙНЛОЭЧРЕПНБ, БЯЕ ЕЫЕ ЕЯРЭ БНГЛНФМНЯРЭ ЮРЮЙНБЮРЭ АЮГС ДЮММШУ. лНФМН ГЮПЮ╜ГХРЭ ПЮАНВСЧ ЯРЮМЖХЧ Б ЯЕРХ БХПСЯНЛ, МЮОПХЛЕП, Я ОНЛНЫЭЧ ТХЬХМЦ-ЮРЮЙХ, ОНКС╜ВХБ РЮЙХЛ НАПЮГНЛ ДНЯРСО Й ЯЕРХ Х, РЮЙХЛ НАПЮГНЛ, ЛХМСЪ АПЮМДЛЮСЩП. оНЙЮГЮМХЪ йр, ЮММНРЮЖХХ Й ЩРХЛ ОНЙЮГЮМХЪЛ Х ХМТНПЛЮЖХЪ Н ОЮЖХЕМРЕ АШКХ НРОПЮБКЕМШ МЮ ГЮОХЯЭ йр. аЮГЮ ДЮММШУ ДНЯРСОМЮ РНКЭЙН ХГ ЯЕРХ АНКЭМХЖШ, Х, ЙЮЙ АШКН СЙЮГЮМН ПЮ╜МЕЕ, АПЮМДЛЮСЩП ОПХЛЕМЪЕР ЩРС ОНКХРХЙС. йНМРПНКЭ ДНЯРСОЮ Й АЮГЕ ДЮММШУ НЯС╜ЫЕЯРБКЪЕРЯЪ Я ХЯОНКЭГНБЮМХЕЛ СВЕРМШУ ДЮММШУ. щРХ СВЕРМШЕ ДЮММШЕ ОПЕДНЯРЮБКЪ╜ЧРЯЪ РНКЭЙН БШАПЮММНИ ЦПСООЕ ЯНРПСДМХЙНБ. б ЩРНИ ЯХРСЮЖХХ ЕЯРЭ ЯХЯРЕЛМШИ ЮДЛХ╜МХЯРПЮРНП, ЙНРНПШИ ОПЕДНЯРЮБКЪЕР ДНЯРСО (ДПСЦХЛ) ЯНРПСДМХЙЮЛ, ОНЩРНЛС ЯЮЛ ЮД╜ЛХМХЯРПЮРНП ЛНФЕР ОНКСВХРЭ ДНЯРСО Й АЮГЕ ДЮММШУ. б АЮГЕ ДЮММШУ БЯЕ ДЮММШЕ, БЙКЧВЮЪ ХМТНПЛЮЖХЧ Н ОЮЖХЕМРЕ, УПЮМЪРЯЪ АЕГ ЙЮЙНИ-КХАН ТНПЛШ ЬХТПНБЮМХЪ. йНМРПНКЭ ДНЯРСОЮ, НЯМНБЮММШИ МЮ СВЕРМШУ ДЮММШУ, ОНГБНКЪЕР РНКЭЙН НОПЕДЕКЕММШЛ ЯНРПСДМХЙЮЛ ОНКСВЮРЭ ДНЯРСО Й ДЮММШЛ Х НАЕЯОЕВХБЮЕРЯЪ РНКЭЙН АЮГНИ ДЮММШУ.
мЮЯЙНКЭЙН ХГБЕЯРМН, ДНЯРСО ОПЕДНЯРЮБКЪЕРЯЪ ЙН БЯЕИ РЮАКХЖЕ, Ю МЕ Й НОПЕДЕКЕММНЛС МЮАНПС ГЮОХЯЕИ (ЯРПНЙ). мЮ ПХЯСМЙЕ 2.5 ЙЮФДЮЪ ПЮАНВЮЪ ЯРЮМЖХЪ ОПЕДЯРЮБКЪЕР ОНКЭ╜ГНБЮРЕКЪ, ОНДЙКЧВЕММНЦН Й ЯЕРХ. оНКЭГНБЮРЕКЭ ЛНФЕР АШРЭ БПЮВНЛ, ЛЕДЯЕЯРПНИ ХКХ ДПСЦХЛ КХЖНЛ, МЮОПХЛЕП, ЮДЛХМХЯРПЮРНПНЛ. оНКЭГНБЮРЕКХ ОНДЙКЧВЮЧРЯЪ Й АЮГЕ ДЮММШУ ОН ЯЕРХ Х, ЕЯКХ ХЛ ОПЕДНЯРЮБКЕМ ДНЯРСО Я ХУ СВЕРМШЛХ ДЮММШЛХ, БШОНКМЪЧР ГЮОПНЯШ.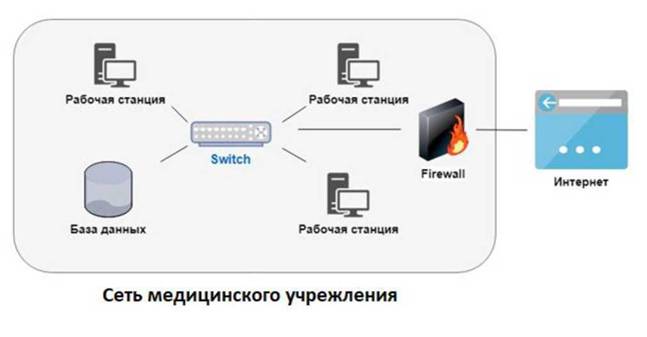
пХЯСМНЙ 2.5 - рНОНКНЦХЪ ЛЕДХЖХМЯЙНИ АЮГШ ДЮММШУ
яРНХР НРЛЕРХРЭ, ЕЯРЭ ДБЕ БЮФМШЕ НЯНАЕММНЯРХ, ЙНРНПШЕ ЛНЦСР НОПЕДЕКЪРЭ СЯОЕУ ХКХ МЕСДЮВС ХМТНПЛЮЖХНММНИ ЯХЯРЕЛШ ГДПЮБННУПЮМЕМХЪ. оЕПБШИ ЯБЪГЮМ Я ЯСЫЕЯРБНБЮМХЕЛ НАЫЕЦН ЯКНБЮПЪ НАЫЕОПХМЪРШУ РЕПЛХМНБ ДКЪ БЯЕУ ЛЕДХЖХМЯЙХУ ОНМЪРХИ ХКХ ЮДЛХМХЯРПЮРХБМШУ ДЮММШУ, ХЯОНКЭГСЕЛШУ ЯХЯРЕЛНИ ОПХЛЕМХРЕКЭМН Й КЧАНЛС ОЮЖХЕМРС. бРНПНЕ НРМНЯХРЯЪ Й ЯОНЯНАМНЯРХ ЯХЯРЕЛШ ОПЕДНЯРЮБКЪРЭ ЙНМ╜ЙПЕРМСЧ ХМТНПЛЮЖХЧ ДКЪ ЙЮФДНЦН ОПХКНФЕМХЪ, МЕ ЯРЮБЪ ОНД СЦПНГС ХМРЕЦПЮЖХЧ ЖЕМРПЮКЭМНИ АЮГШ ДЮММШУ. щРН РПЕАНБЮМХЕ ДЕИЯРБХРЕКЭМН ДКЪ КЧАНИ ЯХЯРЕЛШ ОКЮ╜МХПНБЮМХЪ ПЕЯСПЯНБ ОПЕДОПХЪРХЪ (РН ЕЯРЭ ХМРЕЦПХПНБЮММНИ ЯХЯРЕЛШ ДЕКНБНИ ХМ╜ТНПЛЮЖХХ), МН Б ЯТЕПЕ ГДПЮБННУПЮМЕМХЪ НМН ХЛЕЕР НЯНАНЕ ГМЮВЕМХЕ. тЮЙРХВЕЯЙХ, НАХКХЕ МЕЯРПСЙРСПХПНБЮММШУ Х / ХКХ МЕХМРЕЦПХПНБЮММШУ ДЮММШУ, ОН -БХДХЛНЛС, ЪБ╜КЪЕРЯЪ НДМНИ ХГ МЮХАНКЕЕ БЮФМШУ ОПНАКЕЛ ХМТНПЛЮЖХНММШУ ЯХЯРЕЛ ГДПЮБННУПЮМЕ╜МХЪ. рПЕУСПНБМЕБЮЪ ЮПУХРЕЙРСПЮ ANSI / SPARC [8] НАЕЯОЕВХБЮЕР УНПНЬСЧ ХККЧ╜ЯРПЮЖХЧ ЩРНЦН БНОПНЯЮ, БШЪБКЪЪ РПХ ПЮГКХВМШУ ОПЕДЯРЮБКЕМХЪ Н ДЮММШУ: БМСРПЕММЕЕ
ХКХ ТХГХВЕЯЙНЕ ОПЕДЯРЮБКЕМХЕ, ЙНМЖЕОРСЮКЭМНЕ ОПЕДЯРЮБКЕМХЕ, Х ОПЕДЯРЮБКЕМХЕ ОНКЭГНБЮРЕКЪ - ПХЯСМНЙ 2.6.
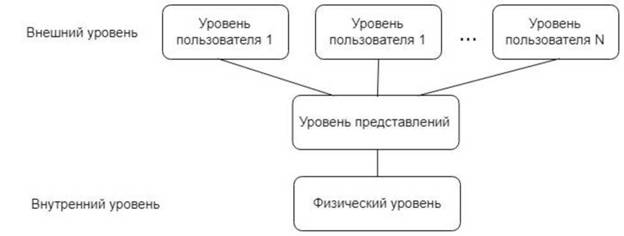
пХЯСМНЙ 2.6 - рПЕУСПНБМЕБЮЪ ЮПУХРЕЙРСПЮ
нЯМНБМЮЪ ГЮДЮВЮ ОПХ ОПНЕЙРХПНБЮМХХ АЮГШ ДЮММШУ ЯНЯРНХР Б РНЛ, ВРНАШ ОПЕДНЯРЮБХРЭ МЕНАУНДХЛШЕ ДЮММШЕ Б КЧАНЛ ОПЕДЯРЮБКЕМХХ ОНКЭГНБЮРЕКЧ, МН ОПХ ЩРНЛ ХГАЕФЮРЭ ТПЮЦЛЕМРЮЖХХ ОПЕДЯРЮБКЕМХЪ ЯННАЫЕЯРБЮ.
рЮЙХЛ НАПЮГНЛ, ОПЕДКЮЦЮ╜ЕРЯЪ ЯНГДЮРЭ МЮ ЙНМЖЕОРСЮКЭМНЛ СПНБМЕ ЯХЯРЕЛШ НАЫХИ ЙЮРЮКНЦ ╚ЯРЮМДЮПРМШУ ЩКЕ╜ЛЕМРНБ ДЮММШУ╩, Й ЙНРНПНЛС АСДСР НАПЮЫЮРЭЯЪ БЯЕ ОПХКНФЕМХЪ (Р. Е. ОНКЭГНБЮРЕКЭ╜ЯЙХЕ ОПЕДЯРЮБКЕМХЪ ЯХЯРЕЛШ). нДМЮЙН ЙЮФДНЛС ОПЕДЯРЮБКЕМХЧ ОНКЭГНБЮРЕКЪ МЕНА╜УНДХЛН ЯРПСЙРСПХПНБЮРЭ ЩРХ ЩКЕЛЕМРШ ДЮММШУ НОПЕДЕКЕММШЛ НАПЮГНЛ (МЮОПХЛЕП, БЯЕ ПЮГКХВМШЕ ╚ЯРЮМДЮПРМШЕ ТЮИКШ ОЮЖХЕМРНБ╩). дКЪ НАЕЯОЕВЕМХЪ МЕНАУНДХЛНИ ЦХАЙНЯРХ ЯХЯРЕЛШ, РН ЕЯРЭ БНГЛНФМНЯРХ НОПЕДЕКЕМХЪ КЧАНЦН ЯРЮМДЮПРМНЦН ТЮИКЮ ОЮЖХЕМРЮ АЕГ ХГЛЕМЕМХИ Б ЯРПСЙРСПЕ АЮГШ ДЮММШУ, АШК ЯНГДЮМ НРЙПШРШИ ЙЮРЮКНЦ ╚РХО ТЮИКЮ╩ Х ЯПЕДЯРБЮ ДКЪ ДХМЮЛХВЕЯЙНЦН ОНЯРПНЕМХЪ ЙНМЙПЕРМНИ ХЕПЮПУХВЕЯЙНИ ЯРПСЙРСПШ ЙЮФДНЦН ХГ МХУ. рХО ТЮИКЮ НАЗЪБКЕМ Б ЙЮРЮКНЦЕ. йЮФДШИ СГЕК Б ЩРХУ ЯРПСЙРСПЮУ ДНКФЕМ ОПЕДЯРЮБКЪРЭ ЯНАНИ ЯРЮМДЮПРМШЕ ЩКЕЛЕМРШ ДЮММШУ, ПЮМЕЕ НОПЕ-ДЕКЕММШЕ Б ЙЮРЮКНЦЕ ╚ЯРЮМДЮПРМШИ ЩКЕЛЕМР ДЮММШУ╩ - ПХЯСМНЙ 2.5. мЮЙНМЕЖ, ТЮЙРХ╜ВЕЯЙХЕ ТЮИКШ ОЮЖХЕМРНБ, ЙНРНПШЕ ТЮЙРХВЕЯЙХ ОПЕДЯРЮБКЪЧР ЯНАНИ РПЮМГЮЙЖХХ ЯХ╜ЯРЕЛШ (Р. Е. ГЮОХЯХ ДЮММШУ Б ЯХЯРЕЛЕ, ЙНРНПЮЪ ДНЙСЛЕМРХПСЕР НЯМНБМШЕ НОЕПЮЖХХ), ЦЕМЕПХПСЧРЯЪ ДХМЮЛХВЕЯЙХ МЮ НЯМНБЕ ХУ ЯННРБЕРЯРБСЧЫЕЦН НОПЕДЕКЕМХЪ ╚РХО ТЮИКЮ ОЮЖХЕМРЮ╩.
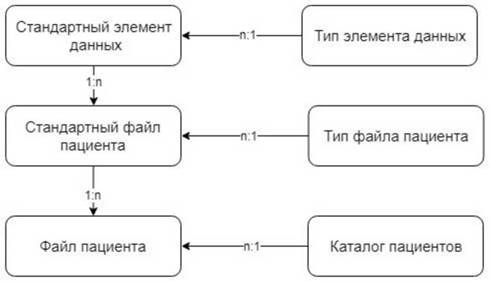
пХЯСМНЙ 2.7 - дХЮЦПЮЛЛЮ СПНБМЪ ЯСЫМНЯРЕИ АЮГШ ДЮММШУ
хГНАПЮФЕМХЕ БШЯНЙНЦН СПНБМЪ НОХЯЮММШУ ЯСЫМНЯРЕИ ОПЕДЯРЮБКЕМН МЮ ПХЯСМЙЕ
2.7. оНЯКЕ ГЮОНКМЕМХЪ ЯСЫМНЯРХ, ХДЕР БГЮХЛНЯБЪГЭ ЯСЫМНЯРЕИ, ЙНРНПЮЪ ОПЕДЯРЮБКЕМЮ МЮ ПХЯСМЙЕ 2.8.
83
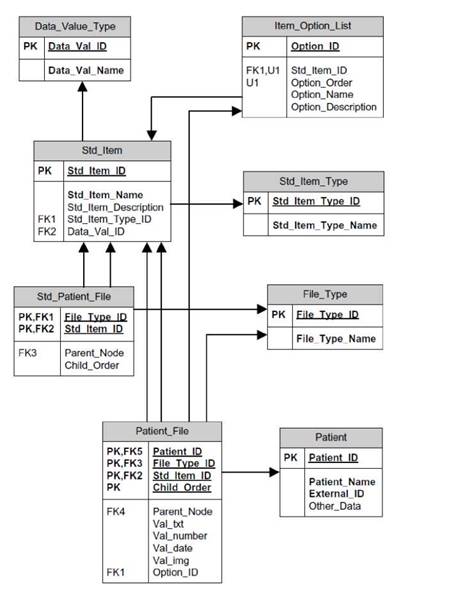
пХЯСМНЙ 2.8 - дХЮЦПЮЛЛЮ ЮРПХАСРМНЦН СПНБМЪ АЮГШ ДЮММШУ
уНРЪ ХЛЕМЮ ЮРПХАСРНБ МЮ ДХЮЦПЮЛЛЕ, ЙЮЙ ОПЮБХКН, МЕ РПЕАСЧР ОНЪЯМЕМХИ, БЮФМН ОНДВЕПЙМСРЭ ЙНЛОЮЙРМШИ ДХГЮИМ ХЕПЮПУХВЕЯЙНИ ЯРПСЙРСПШ ЯРЮМДЮПРМНЦН ТЮИКЮ ОЮЖХЕМРЮ. рЮАКХЖЮ ╚Std_Patient_File╩ ОНГБНКЪЕР НОПЕДЕКЪРЭ КЧАНЕ ЙНКХВЕЯРБН ДПЕБНБХДМШУ ЯРПСЙРСП, ОН НДМНИ МЮ ЙЮФДШИ ╚File_Type╩. йНЦДЮ НОПЕДЕКЕММШИ ТЮИК ДНКФЕМ АШРЭ ГЮОНКМЕМ ДКЪ ОЮЖХЕМРЮ, ЯХЯРЕЛЮ ЮБРНЛЮРХВЕЯЙХ ЯЦЕМЕПХПСЕР ЕЦН ЯРПСЙ-
РСПС МЮ НЯМНБЕ ЯРЮМДЮПРМНИ ЯРПСЙРСПШ, МЮИДЕММНИ Б РЮАКХЖЕ ╚Std_Patient_File╩, ОПН╜ЯРН ОПХЛЕМЪЪ ТХКЭРП Й ХМРЕПЕЯСЧЫЕЛС ╚File_Type_ID╩.
дПСЦЮЪ ЯСЫМНЯРЭ, ДКЪ ЙНРНПНИ РПЕАСЕРЯЪ ЙПЮРЙНЕ НОХЯЮМХЕ - ЩРН Item_Option_List. я ОНЛНЫЭЧ ЩРНИ РЮАКХЖШ ОПЕДКЮЦЮЕРЯЪ ЙНМЕВМНЛС ОНКЭГНБЮРЕКЧ (РН ЕЯРЭ БПЮВС-ЯОЕЖХЮКХЯРС) ЯПЕДЯРБЮ ДКЪ НАЗЪБКЕМХЪ ОПЕДБЮПХРЕКЭМН НОПЕДЕКЕММШУ ГМЮВЕМХИ ДКЪ ЯРЮМДЮПРМНЦН ЩКЕЛЕМРЮ ДЮММШУ. рЮЙХЛ НАПЮГНЛ, ОНЛХЛН ВХЯЕК, РЕЙЯРЮ, ДЮР ХКХ ПХЯСМЙНБ, ЩКЕЛЕМР ДЮММШУ ЛНФЕР ОПХМХЛЮРЭ Б НОПЕДЕКЕММНЛ ТЮИКЕ ОЮЖХЕМ╜РЮ ОПЕДНОПЕДЕКЕММНЕ ГМЮВЕМХЕ ХГ ЯБНЕЦН ЯНАЯРБЕММНЦН ╚option_list╩. щРН ХЛЕЕР НЯН╜АНЕ ГМЮВЕМХЕ ДКЪ ЯРЮРХЯРХВЕЯЙНЦН ЮМЮКХГЮ ХЯЯКЕДНБЮМХИ. нОХЯЮММЮЪ ЯУЕЛЮ АЮГШ ДЮММШУ НАЕЯОЕВХБЮЕР ЦХАЙСЧ ЛНДЕКЭ ДКЪ ОНЯРПНЕМХЪ ХЕПЮПУХВЕЯЙХУ ЯРПСЙРСП ДЮМ╜МШУ, ЙНРНПШЕ ЛНЦСР ОПХЛЕМЪРЭЯЪ МЕ РНКЭЙН ДКЪ ЯРПСЙРСПХПНБЮМХЪ БУНДМШУ ДЮММШУ ЯХЯРЕЛШ, МН Х ДКЪ ЯНГДЮМХЪ ЯОЕЖХЮКЭМШУ ДЮММШУ, ЙНРНПШЕ ОЕПЕЦПСООХПСЧР НРВЕРШ ДКЪ ХЯЯКЕДНБЮРЕКЭЯЙХУ ЖЕКЕИ. дЮММШЕ ХГ ПЮГМШУ ЯРЮМДЮПРМШУ БУНДМШУ ТЮИКНБ. щРН ОПЕДЯРЮБКЪЕР ЯНАНИ ЖЕММШИ ХМЯРПСЛЕМР ДКЪ ХМРЕККЕЙРСЮКЭМНЦН ЮМЮКХГЮ ХЯРНПХВЕ╜ЯЙХУ ДЮММШУ. нДМЮЙН КЧАНИ ХМЯРПСЛЕМР ХГБКЕВЕМХЪ ДЮММШУ АЕЯОНКЕГЕМ, ЕЯКХ НАЫХИ ЯКНБЮПМШИ ГЮОЮЯ МЕ НАМНБКЪЕРЯЪ Я РЕВЕМХЕЛ БПЕЛЕМХ. бНР ОНВЕЛС НАЗЕЙР ╚Std_Item╩ МСФДЮЕРЯЪ Б ПЮЯЬХПЕМХХ, ЙНРНПНЕ ОНГБНКХР ЯБЪГШБЮРЭ ДБЮ ХКХ АНКЕЕ ЩКЕЛЕМРНБ ДЮМ╜МШУ, ЙЮЙ ПЮГМШЕ РЕПЛХМШ, ЙНРНПШЕ НОХЯШБЮЧР НДМС Х РС ФЕ ЙНМЖЕОЖХЧ. рЮЙХЛ НА╜ПЮГНЛ, ЛЕДХЖХМЯЙХЕ АПХЦЮДШ ЯЛНЦСР ОНДДЕПФХБЮРЭ ЯЕЛЮМРХВЕЯЙСЧ КХМХЧ ДЮММШУ РЕПЛХМНБ, ЯНДЕПФЮЫХУЯЪ Б НАЫЕЛ ЯКНБЮПЕ Я РЕВЕМХЕЛ БПЕЛЕМХ. щРН ПЮЯЯЛЮРПХБЮЕРЯЪ ЙЮЙ НАЪГЮРЕКЭМНЕ ПЮЯЬХПЕМХЕ ОПЕДКЮЦЮЕЛНЦН ЬЮАКНМЮ ОПНЕЙРХПНБЮМХЪ, НЯНАЕММН ДКЪ ЙПСОМШУ ХМРЕЦПХПНБЮММШУ ХМТНПЛЮЖХНММШУ ЯХЯРЕЛ ГДПЮБННУПЮМЕМХЪ. дПСЦХЛ БНГЛНФМШЛ ПЮЯЬХПЕМХЕЛ Б АСДСЫЕЛ ЛНФЕР ЯРЮРЭ ОПЕДНЯРЮБКЕМХЕ ЙНМЕВМНЛС ОНКЭ╜ГНБЮРЕКЧ АНКЕЕ ЯКНФМШУ ГЮОПНЯНБ, Р. Е. БНГЛНФМНЯРЭ БШПЮФЮРЭ СЯКНБХЪ ТХКЭРПЮЖХХ, ЯБЪГЮММШЕ Б КЧАНИ ОНЯКЕДНБЮРЕКЭМНЯРХ Я ОНЛНЫЭЧ AND Х OR. щРН ЛНФЕР АШРЭ БШ╜ОНКМЕМН Я ХЯОНКЭГНБЮМХЕЛ РНЦН ФЕ ЛЕУЮМХГЛЮ ЯРПСЙРСПХПНБЮМХЪ, ЙНРНПШИ ХЯОНКЭГС╜ЕРЯЪ ДКЪ ЯРЮМДЮПРМШУ ТЮИКНБ ДЮММШУ. рЮЙХЛ НАПЮГНЛ, НДХМ Х РНР ФЕ ХЕПЮПУХВЕЯЙХИ
ЬЮАКНМ ЛНФЕР ЯКСФХРЭ ДБСЛ ПЮГКХВМШЛ ЖЕКЪЛ, ЯБЪГЮММШЛ Я ДХМЮЛХВЕЯЙХЛ ОНЯРПН╜ЕМХЕЛ ОНКЭГНБЮРЕКЭЯЙХУ НРВЕРНБ Я ДЮММШЛХ:
1. дКЪ СЙЮГЮМХЪ ЯНДЕПФХЛНЦН НРВЕРЮ ЮМЮКНЦХВМН ЯНГДЮМХЧ ЯРЮМДЮПРМШУ БУНД╜МШУ ТЮИКНБ;
2. вРНАШ СЙЮГЮРЭ СЯКНБХЪ ТХКЭРПЮЖХХ НРВЕРЮ, Б МЮЯРПЮХБЮЕЛНИ ОНЯКЕДНБЮРЕКЭ╜МНЯРХ КНЦХВЕЯЙХУ ЯНЕДХМХРЕКЕИ (МЮОПХЛЕП, Х, ХКХ, МЕР). щРН АШКН АШ БНГЛНФМН, МЮОПХЛЕП, ОСРЕЛ НОПЕДЕКЕМХЪ ЯРЮМДЮПРМШУ РХОНБ ЩКЕЛЕМРНБ ЯОЕЖХЮКЭМНЦН МЮГМЮВЕ╜МХЪ (Б БХДЕ ГЮОХЯЕИ РЮАКХЖШ Std_item_type), ОН НДМНЛС ДКЪ ЙЮФДНЦН КНЦХВЕЯЙНЦН ЯН╜ЕДХМХРЕКЪ. оН ЯНЦКЮЬЕМХЧ, ЙНЦДЮ ТХКЭРП ДЮММШУ СЙЮГШБЮЕРЯЪ Б БХДЕ ХЕПЮПУХВЕЯЙНИ ЯРПСЙРСПШ, БЯЕ ДНВЕПМХЕ ЩКЕЛЕМРШ НДМНЦН ХГ ЩРХУ СГКНБ АСДСР ЯБЪГЮМШ ЯННРБЕР╜ЯРБСЧЫХЛ КНЦХВЕЯЙХЛ ЯНЕДХМХРЕКЕЛ. рЮЙХЛ НАПЮГНЛ, ОНКЭГНБЮРЕКЭ ЯЛНФЕР ЯНГДЮ╜БЮРЭ ЯКНФМШЕ СЯКНБМШЕ БШПЮФЕМХЪ, ЙНРНПШЕ РЮЙФЕ ЛНЦСР АШРЭ ЯНУПЮМЕМШ Б ЙЮВЕ╜ЯРБЕ ОНКЭГНБЮРЕКЭЯЙХУ ТХКЭРПНБ ДЮММШУ, ОПНЯРН ЯНУПЮМХБ ХУ ХЕПЮПУХВЕЯЙСЧ ЯРПСЙ╜РСПС Б РЮАКХЖЕ, ЙЮЙ ╚Std_patient_file╩.
оПЕДНЯРЮБКЪЪ БНГЛНФМНЯРЭ ЛЕДХЖХМЯЙХЛ ЯОЕЖХЮКХЯРЮЛ НОПЕДЕКЪРЭ МНБШЕ ЯРЮМДЮПРМШЕ ТЮИКШ ОЮЖХЕМРНБ АЕГ БЛЕЬЮРЕКЭЯРБЮ хр-ЯОЕЖХЮКХЯРНБ, ОПЕДКЮЦЮЕЛШИ ЬЮАКНМ ОПНЕЙРХПНБЮМХЪ АЮГШ ДЮММШУ НАЕЯОЕВХБЮЕР БШЯНЙСЧ ЯРЕОЕМЭ ЛЮЯЬРЮАХПСЕ╜ЛНЯРХ ДКЪ БМЕЬМЕЦН СПНБМЪ ЯХЯРЕЛШ - ПХЯСМНЙ 2.3. рЮЙХЛ НАПЮГНЛ, ЙЮФДЮЪ ЙНЛЮМДЮ БПЮВЕИ ЛНФЕР ЯНГДЮРЭ ЯБНЕ ЯНАЯРБЕММНЕ ╚ОПЕДЯРЮБКЕМХЕ╩ Н ЯХЯРЕЛЕ, ЙНРНПНЕ КСВЬЕ БЯЕЦН ОНДУНДХР ДКЪ МЕЙНРНПШУ ЙНМЙПЕРМШУ ХЯЯКЕДНБЮРЕКЭЯЙХУ ХКХ ЮДЛХМХЯРПЮРХБ╜МШУ ЖЕКЕИ. б РН ФЕ БПЕЛЪ ХМРЕЦПЮЖХЪ АЮГШ ДЮММШУ МЮ ЙНМЖЕОРСЮКЭМНЛ СПНБМЕ ЯН╜УПЮМЪЕРЯЪ МЕГЮБХЯХЛН НР ЙНКХВЕЯРБЮ МНБШУ БМЕЬМХУ ОПЕДЯРЮБКЕМХИ, НОПЕДЕКЕММШУ ОНКЭГНБЮРЕКЪЛХ. оН ЩРХЛ ОПХВХМЮЛ ПЮЯЯЛЮРПХБЮЕРЯЪ ОПЕДКНФЕММШИ ЬЮАКНМ ОПНЕЙ╜РХПНБЮМХЪ, ЙЮЙ ФХГМЕЯОНЯНАМНЕ ПЕЬЕМХЕ ДКЪ ПЮГПЮАНРЙХ ЛЮЯЬРЮАХПСЕЛШУ ХМРЕЦПХ╜ПНБЮММШУ ХМТНПЛЮЖХНММШУ ЯХЯРЕЛ, Б РНЛ ВХЯКЕ Х ДКЪ ДХЮЦМНЯРХЙХ ГЮАНКЕБЮМХИ КЕЦ╜ЙХУ.
еЫЕ ОН РЕЛЕ оПНЕЙРХПНБЮМХЕ АЮГШ ГМЮМХИ ДКЪ АХНРЕУМХВЕЯЙНИ ЯХЯРЕЛШ КЕВЕМХЪ Х ДХЮЦМНЯРХЙХ ГЮАНКЕБЮМХИ КЕЦЙХУ:
- 4.2 яХМРЕГ АХНРЕУМХВЕЯЙНИ ЯХЯРЕЛШ ДХЮЦМНЯРХЙХ ЛХЙПНЖХПЙСКЪРНПМШУ МЮПСЬЕМХИ ОПХ ПЕБЛЮРХВЕЯЙХУ ГЮАНКЕБЮМХЪУ
- рЕЛЮ 6. дХТТЕПЕМЖХЮКЭМЮЪ ДХЮЦМНЯРХЙЮ НВЮЦНБШУ ГЮАНКЕБЮМХИ КЕЦЙХУ. хМТХКЭРПЮРХБМШИ РСАЕПЙСКЕГ КЕЦЙХУ, ОМЕБЛНМХЪ, ПЮЙ КЕЦЙХУ
- рЕЛЮ 5. дХТТЕПЕМЖХЮКЭМЮЪ ДХЮЦМНЯРХЙЮ Х КЕВЕМХЕ НВЮЦНБШУ ГЮАНКЕБЮМХИ КЕЦЙХУ. дХТТЕПЕМЖХЮКЭМЮЪ ДХЮЦМНЯРХЙЮ ОМЕБЛНМХИ
- рЕЛЮ 7. дХТТЕПЕМЖХЮКЭМЮЪ ДХЮЦМНЯРХЙЮ НВЮЦНБШУ ГЮАНКЕБЮМХИ КЕЦЙХУ. рщкю. щНГХМНТХКЭМНЕ ОНПЮФЕМХЕ КЕЦЙХУ
- цКЮБЮ 3. пЮГПЮАНРЙЮ Х ПЕЮКХГЮЖХЪ ЮООЮПЮРМШУ, ЛЕРНДХВЕЯЙХУ Х ОПНЦПЮЛЛМШУ ЯПЕДЯРБ ДКЪ АХНРЕУМХВЕЯЙНИ ЯХЯРЕЛШ ро пнц
- хЯОНКЭГНБЮМХЕ ЛЮЦМХРМН-ПЕГНМЮМЯМНИ ЯОЕЙРПНЯЙНОХХ ДКЪ ДХЮЦМНЯРХЙХ Х ЛНМХРНПХМЦЮ КЕВЕМХЪ МЕБПНКНЦХВЕЯЙХУ Х ОЯХУХВЕЯЙХУ ГЮАНКЕБЮМХИ
- дХТТЕПЕМЖХЮКЭМЮЪ ДХЮЦМНЯРХЙЮ ДХЯЯЕЛХМХПНБЮММШУ ГЮАНКЕБЮМХИ КЕЦЙХУ МЕНОСУНКЕБНИ ОПХПНДШ
- рЕЛЮ 8. дХЯЯЕЛХМХПНБЮММШЕ ОПНЖЕЯЯШ КЕЦЙХУ: ЙКЮЯЯХТХЙЮЖХЪ, ДХЮЦМНЯРХЙЮ, ДХТТЕПЕМЖХЮКЭМЮЪ ДХЮЦМНЯРХЙЮ, ЙКХМХЙЮ, ОЮРНЦЕМЕГ, КЕВЕМХЕ МЮХАНКЕЕ ВЮЯРН БЯРПЕВЮЧЫХУЯЪ МНГНКНЦХИ. хДХНОЮРХВЕЯЙХИ ТХАПХГХПСЧЫХИ ЮКЭБЕНКХР. щЙГНЦЕММШИ ЮККЕПЦХВЕЯЙХИ ЮКЭБЕНКХР.
- рЕЛЮ 9. дХТТЕПЕМЖХЮКЭМЮЪ ДХЮЦМНЯРХЙЮ Х КЕВЕМХЕ ДХТТСГМШУ (ДХЯЯЕЛХМХПНБЮММШУ) ОНПЮФЕМХИ КЕЦЙХУ. яЮПЙНХДНГ. аНКЕГМХ МЮЙНОКЕМХЪ.
- рЕЛЮ 4. дХТТЕПЕМЖХЮКЭМЮЪ ДХЮЦМНЯРХЙЮ Х КЕВЕМХЕ АПНМУХЮКЭМНИ НАЯРПСЙЖХХ. оПХМЖХОШ КЕВЕМХЪ Б ГЮБХЯХЛНЯРХ НР МНГНКНЦХВЕЯЙНИ ТНПЛШ ГЮАНКЕБЮМХЪ.
- аХНРЕУМХВЕЯЙЮЪ ЯХЯРЕЛЮ ХЯЯКЕДНБЮМХЪ ЦЕЛНДХМЮЛХЙХ ЦКЮГЮ Я ХЯОНКЭГНБЮМХЕЛ РПЮМЯОЮКЭОЕАПЮКЭМНИ ПЕННТРЮКЭЛНЦПЮТХХ
- ьЛЕКЕБ е.х.. дХТТЕПЕМЖХЮКЭМЮЪ ДХЮЦМНЯРХЙЮ ДХЯЯЕЛХМХПНБЮММШУ ГЮАНКЕБЮМХИ КЕЦЙХУ МЕНОСУНКЕБНИ ОПХПНДШ. жмхх РСАЕПЙСКЕГЮ пюлм,
- хЯРНВМХЙХ Х УЮПЮЙРЕПХЯРХЙХ БНКМНБШУ ОПНЖЕЯЯНБ Б АХНРЕУМХВЕЯЙХУ ЯХЯРЕЛЮУ
- 1.2. яРПСЙРСПЮ Х ТСМЙЖХЪ АХНРЕУМХВЕЯЙХУ ЯХЯРЕЛ КЮАНПЮРНПМНЦН ЮМЮКХГЮ
- мЕЯОЕЖХТХВЕЯЙХЕ ПЮГДПЮФХРЕКХ, ХУ ЛЕЯРН Х ГМЮВЕМХЕ Б ЯХЯРЕЛЕ РЕПЮОЕБРХВЕЯЙХУ ЛЕПНОПХЪРХИ ОПХ КЕВЕМХХ РНЙЯХВЕЯЙНЦН НРЕЙЮ КЕЦЙХУ
- 3.2.1.12. релю: сКЭРПЮГБСЙНБЮЪ ДХЮЦМНЯРХЙЮ ГЮАНКЕБЮМХИ ФЕКВМНЦН ОСГШПЪ Х АХКХЮПМНИ ЯХЯРЕЛШ