Блок управления бустингом и алгоритмы его работы
Как было показано в разделе 3.1, для улучшения показателей качества прогнозирования ИР в структурной функциональной модели принятия решений используются два параллельных канала, что позволяет использовать технологию бустинга.
Каждый канал выдает свое решение по прогнозу ишемического риска (ИР). Для того, чтобы выбрать лучшее из них, необходим блок управления бустингом (БУБ), позволяющая осуществить такой выбор.При построении БУБ необходимо учитывать, что принятие решений по ИР осуществляется на основе коэффициентов уверенности КУ1, КУ2, КУ3, поступающих с выходов математических моделей ИР, построенных во втором разделе.
Для построения БУБ воспользуемся методологией обучаемых классификаторов. Для построения обучаемого классификатора необходимо построить таблицу “объект - признак”. В таблице 3.2 представлена структура данных для БУБ.
Таблица 3.2 - Структура данных обучаемого классификатора для блока управления бустингом
| Признак Объект | КУ1 | КУ2 | КУЗ | Решения 1 верно | Решение 2 верно | Y |
| 1 | 0.5 | 0.3 | 0.4 | 1 | 0 | +1 |
| 2 | 0.8 | 0.6 | 0.7 | 0 | 1 | -1 |
| ... | ... | ... | ... | ... | ... | |
| N | 0.6 | 0.8 | 0.9 | 0 | 1 | +1 |
Таблица 3.2 показывает, что для каждого объекта из обучающей выборки необходимо запомнить, какое решение из двух классификаторов предпочтительно.
Так как каждое сочетание {КУ1, КУ2, КУ3} уникально, то БУБ должен быть построен на основе аппроксиматора, позволяющего выполнить обобщение свойств множеств {КУ1, КУ2, КУ3} в окрестностях точек четырехмерного пространства, принадлежащих обучающей выборки. Такое обобщение можно сделать на базе радиальных или вероятностных НС [95, 131]. Однако при решении данной задачи прогнозировать структуру пространства признаков очень сложно, так как оно само порождается моделями с неизвестной адекватностью. Нерегулярность таких экспериментальных данных накладывает определенные ограничения на использование классических НС, так как новые наблюдения могут потребовать переобучение сети [30]. Поэтому в качестве БУБ выбрана модель, которая позволяет неограниченно наращивать число запоминаемых точек, то есть до минимума снижать размеры окрестности у объектов обучающей выборки.
В одном из крайних (частных) случаев все точки четырехмерного пространства {КУ1, КУ2, КУ3} - пространства (n + 1) можно разделить одной гиперплоскостью (в данном случае имеем дело с двумя классами: “Решение 1 верно” и “Решение 2 верно”). Если это удастся сделать, то разделяющая (дискриминантная) гиперплоскость f-f может быть найдена на основе алгоритма линейного дискриминантного анализа Фишера (ЛДА) [1, 2]:
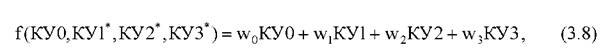
где КУ0= 1; w0, w1, w2, w3- весовые коэффициенты.
В соответствии с этим алгоритмом весовым коэффициентам присваивают начальные (как правило, нулевые) значения, а затем последовательно рассчитывается значения дискриминантной функции (3.8).
Если закодировать классы числами +1 и -1, то решение в БУБ для не нулевого образца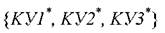
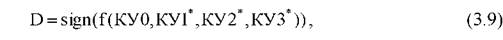
где sign - функция знака, равная +1 для положительных и -1 для отрицательных значений аргумента.
Алгоритмы ассоциативного выбора решений заключается в следующем:
1. Формируется обучаемый классификатор, желательно построенный на парадигме, отличной от парадигмы, используемых в классификаторах, используемых в каналах «Решение 1» и «Решение 2».
2. Формируется контрольная выборка для классификаторов «Решение 1» и «Решение 2».
3. По результатам классификации по контрольной выборке формируется множество целей переменной ass: 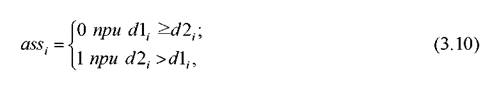
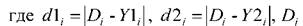 - цель для i-го образца, Y 1i∙ - выход канала 1 для i-го образца, Y2i- выход канала 2 для i-го образца.
- цель для i-го образца, Y 1i∙ - выход канала 1 для i-го образца, Y2i- выход канала 2 для i-го образца.
4. Формируем новую обучающую выборку для классификатора
дублирующих каналов путем объединения множества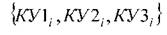 и
и
множества {assi}, где элементы первого множества являются независимыми переменными, а элемент второго множества являются множеством элементов цели.
5. Настраиваем классификатор дублирующих каналов по обучающей
выборке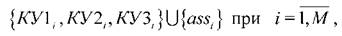 где M - число образцов в
где M - число образцов в
контрольной выборке, используемой для формирования множества (3.10).
За основу построения классификатора БУБ возьмем промежуточный вариант, лежащий между запоминанием всех образцов и ЛДА. Предлагаемый алгоритм базируется на построении множества локальных моделей линейного вида, предложенных в [105].
Для аппроксимации пространства используется
используется
аппроксимирующая функция:

состоящая из суперпозиции функции вида:
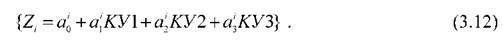
В силу нелинейности (3.11) зависимости (3.12) строятся для некоторой области iаргументов в которой с заранее установленной
в которой с заранее установленной
погрешностью выражение (3.11) может быть адекватно приближению линейной зависимости (3.12).
Таким образом, задача построения БУБ сводится к построению алгоритма кусочно-линейной аппроксимации нелинейной зависимости в четырехмерном пространстве.
Набор аппроксимирующих функций строится последовательно, для обучающих образцов, образующих в многомерном пространстве выпуклые области (базовые элементы), а с поступлением новых наблюдений корректируется в соответствии с алгоритмом, включающим следующую последовательность действий:
1) на основе серии экспериментов определить первый базовый элемент в пространстве данных и включить соответствующие ему точки в базу обучающих образцов, то есть определяем четыре точки в пространстве (3.11) и строим гиперчетырехугольник;
2) провести новый эксперимент и получить новые данные, следующую точку в четырехмерном пространстве;
3) проверить условие попадания новых данных в область базовых элементов;
4) если новые данные выходят за пределы области базовых элементов, добавить их в базу обучающих образцов и сформировать новую совокупность базовых элементов, расширяя, таким образом, область покрытия функции (3.11) и перейти к п. 2 алгоритма;
5) если новые данные попадают в область базовых элементов, то провести оценку адекватности базы обучающих образцов по новым данным;
6) если база обучающих образцов адекватна новым данным, то перейти к п. 2 алгоритма;
7) если база обучающих образцов неадекватна новым данным, включить их в базу и провести ее разбиение на новые базовые элементы с учетом этих данных;
8) перейти к п.2 алгоритма и т.д. до обработки всей совокупности таблицы «объект - признак» типа таблицы 3.2.
Так как данные таблицы 3.2 представляют собой точки в четырехмерном пространстве, то для построения моделей (3.12) необходимо не менее четырех таких точек. Для определения уравнения гиперплоскости используем одно из
уравнений множества (3.12). Из этого множества образуем базовые элементы, которые назовем гиперчетырехугольниками, покрывающие область построения модели (область, определяемую тремя первыми и последним столбцами таблицы 3.2). При добавлении нового образца из таблицы 3.2 необходимо проверить его попадание в область базовых элементов уже созданных на основе предшествующих данных таблицы 3.2.
Существует несколько решений такой задачи (методы трассировки луча; суммирование углов; подсчета числа оборотов границы и др.) [5].В диссертации используется упрощенный способ ее решения, который базируется на свойстве выпуклых многоугольников [5]. Так, из рисунка 3.8 видно, что если некоторая точка P0не принадлежит к области, ограниченной выпуклым гипермногоугольником P1, P2, P3, P4, то она всегда может быть разделена с ним в пространстве линией (гиперплоскостью) f-f.
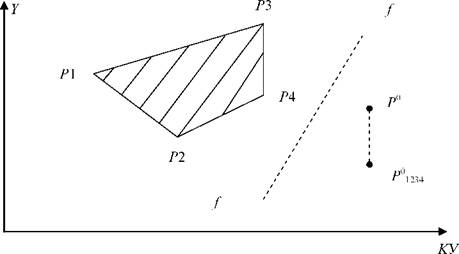
Рисунок 3.8 - Оценка принадлежности точки базовому элементу
Точка P01234является проекцией некоторого экспериментального наблюдения P0на плоскость, проходящую через точки P1, P2, P3, P4. Координаты проекции P01234могут быть найдены по уравнению, списывающему гиперплоскость P1, P2, P3, P4(базовый элемент). Построение соответствующих
зависимостей хорошо разработано и может базироваться, например, на применении метода наименьших квадратов [1, 2].
Для определения коэффициентов a0, a1, a2, a3,определяющих положение четырехмерной плоскости, использовалась система уравнений:
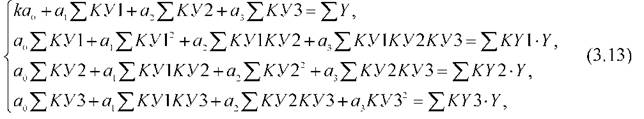
где к - количество экспериментальных наблюдений, через которые проведена гиперплоскость (при использовании описанных выпуклых базовых элементов применительно к системе (3.12) оно равно четырем). Если точка P0не принадлежит к классу точек {P1, P2, P3, P4}, то значения признаков (3.10) будут иметь разные знаки.
При условии линейной разделимости точек P1, P2, P3, P4 и точки P0, что справедливо для выпуклых базовых элементов, значения признака Dбудут иметь разные знаки для класса точек P1, P2, P3, P4и класса, содержащего точку P0.
Значение весовых коэффициентов в процессе обучения будут корректироваться по формуле:
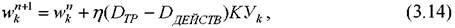
где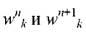 - значение коэффициента wkна п -м и (п+1)-м этапе обучения;
- значение коэффициента wkна п -м и (п+1)-м этапе обучения;
η- мера обучения (число от 0 до 1, характеризующее скорость и точность обучения);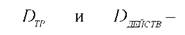 требуемое и действительное значения
требуемое и действительное значения
классификационного признака (например, требуемое значение для класса точек P1, P2, P3, P4- значение +1; для класса, содержащего точку P0, требуемое значение: -1); КУк- значение координаты, соответствующей коэффициенту wk.
При малом количестве точек, что характерно для решаемой задачи, итерационные вычисления (3.14) сходятся очень быстро. В результате после заранее заданного количества повторений классификация оказывается успешной для всех точек обоих классов, если проекция P01234располагается внутри базового элемента.
Если наблюдение попадает за пределы области базовых элементов, его добавляют в базу обучающих образцов и формируют новую совокупность базовых элементов (рисунок 3.9). Так, при добавлении точки P0в базу обучающих образцов, содержавшую ранее точки P1, P2, P3, P4и, соответственно, список базовых элементов, содержащий единственный элемент P1P2P3P4, поступают следующим образом.
Для добавляемой точки P0в четырехмерном пространстве задачи находят три ближайших к ней точек из базы обучающих образцов и соединяют ее с ними, образуя новый базовый элемент (рисунке 3.8). Этот элемент заносят в соответствующий список, который в соответствии с рисунком 3.3 станет содержать два базовых элемента - P1P2P3P4и P0P2P3P4.
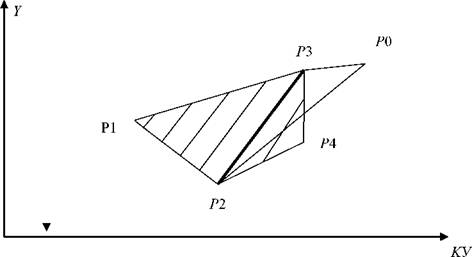
Рисунок 3.9 - Иллюстрация формирования нового элемента
Если образец попадает в область одного из базовых элементов, то проверяют адекватность этого базового элемента данному образцу. Получаем
новое наблюдение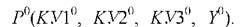 При попадании его в область
При попадании его в область
базового элемента необходимо определить его расстояние (.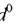 от соответствующей этому базовому элементу гиперплоскости (образец в частном случае может лежать и в ней). Величина такого расстояния является мерой адекватности базового элемента текущему наблюдению.
от соответствующей этому базовому элементу гиперплоскости (образец в частном случае может лежать и в ней). Величина такого расстояния является мерой адекватности базового элемента текущему наблюдению.
Для нахождения расстояния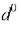 используется аппроксимирующая
используется аппроксимирующая
зависимость (3.12), найденная путем решения соответствующей системы уравнений (3.13).
Если для расстояния d0выполняется условие:
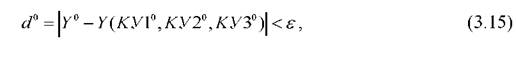
где Y0- фактическое положение наблюдения в пространстве; Y(КУ10, КУ20, КУ30) - проекция наблюдения на гиперплоскость базового элемента; ε- заранее принятая мера неадекватности модели экспериментальным наблюдениям, то точка находится вблизи от гиперплоскости и соответствующий базовый элемент адекватно описывает новое наблюдение. В этой связи добавлять указанное наблюдение в базу обучающих образцов не имеет смысла, и соответствующая точка исключается из рассмотрения (п.6 алгоритма).
Если проверка выявила неадекватность базы обучающих образцов новому наблюдению, следует включить его в базу и провести ее повторное разбиение на базовые элементы с учетом нового наблюдения (п.7 алгоритма).
Если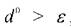 , то базовый элемент P1P2P3P4не адекватен нелинейной
, то базовый элемент P1P2P3P4не адекватен нелинейной
зависимости (3.10) в области, ограниченной точками P1, P2, P3, P4(рисунок 3.9). Поэтому на поверхности отклика располагаем кроме образцов P1, P2, P3, P4, и образец P0.
С этой целью для точки P0в четырехмерном пространстве находят все возможные комбинации из четырёх точек неадекватного базового элемента и соединяют ее с ними, образуя, таким образом, четыре новых базовых элемента.
Эти элементы заносят в соответствующий список, из которого затем удаляется прежний, неадекватный, базовый элемент.
Список, ранее включавший только элемент P1P2P3P4, после корректировки станет содержать четыре базовых элемента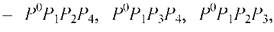
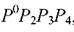 , а кусочно-линейная поверхность отклика станет иметь локальный экстремум в точке
, а кусочно-линейная поверхность отклика станет иметь локальный экстремум в точке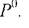
Описанные операции алгоритма повторяются применительно ко всей совокупности наблюдений или до получения удовлетворительного результата работы обученной программы. При этом в ее памяти сохраняются списки базовых элементов, а также уравнения, описывающие элементы.
Использование обученной программы для решения практических задач сводится к многомерной интерполяции данных, когда для заданного набора аргументов КУ\°, КУ20, КУ30требуется определить значение выходной переменной Y0.
В этом случае программой просматривается список базовых элементов и проверяется условие попадания текущего набора аргументов внутрь одного из элементов. Значение выходной переменной Y0находится из уравнения, описывающего соответствующий элемент.
Еще по теме Блок управления бустингом и алгоритмы его работы:
- Адаптивное управление разверткой видеокадра. Алгоритм управления
- 3.3 Алгоритм управления процессами принятия решений
- Алгоритм управления системы поддержки принятия решений.
- 3.3 Алгоритм управления процессами принятия решений
- 4.1. Алгоритм управления системой поддержки принятия решений
- Алгоритм управления процессами принятия решений в интеллектуальной системе оценки риска и профессиональныхзаболеваний водителей транспортных средств экстренных служб
- Алгоритм синтеза общего описания потоков работ
- 47. Принципы работы психолога. Его права и обязанности. Индивидуальный подход в работе психолога
- Примеры алгоритмов функционирования рабочих групп по управлению КМП в подразделениях многопрофильного ЛПУ
- Функции системы управления потоками работ
- Модуль принятия решений на основе бустинга
- Хранение культуры продуцента и подготовка его к работе
- 3.5. Результаты исследований управления ритмом сердца средствами его акустической имитации
- 4.1. Выбор вида коммерческой деятельности для медицинского учреждения в зависимости от основного направления его работы
- Функциональное биологическое управление и морфо-функицональное обоснование его применения при расстройствах мочеиспускания неорганического генеза и СНФТО у детей.
- Приложение 5. Программа тренинга «Стресс в работе специалистов пенсионных отделов. Способы управления стрессом»