Модуль принятия решений на основе бустинга
Для разработки модуля прогнозирования возникновения ПКРна основе бустинга был использован линейный дискриминантный анализ. Идея использования линейного дискриминантного анализа для прогнозирования ПКР заключается в следующем.
Имеется 2 группы водителей, у одних из которых высокий риск заболеванияПКР (группа А), у других низкий (группа В). Каждый из водителей в этих группах обследуется в отношении влияния на него комплекса, состоящего из «факторов риска. В абстрактном «-мерном пространствегеометрические центры обеих групп будут отстоять друг от друга на определенном расстоянии. По величине этого расстояния можно судить о статистической достоверности различия группЛи В. Обследовав конкретного водителя по факторам риска, можно вычислить, по какую сторону разделяющей гиперплоскости (дискриминатора) располагается точка, отражающая положение испытуемого в //-мерном пространстве. Расстояние этой точки до центров групп отражает степень ее принадлежности к каждой из них. Графическая интерпретация данной идеи приведена на рисунке 3.4.
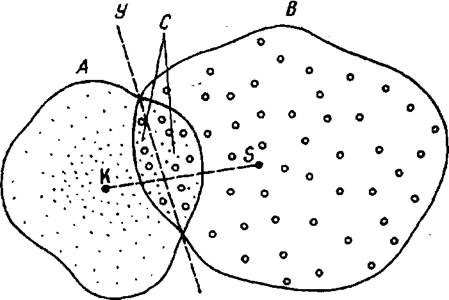
Рисунок 3.4 -Схема дискриминантного анализа:
К - центр группыЛ(наблюдения обозначены точками);
S - центр группы В (наблюдения обозначены кружочками);
KS - расстояние Махаланобиса; С - зона неопределенности;
У - дискриминатор
Для вычисления дискриминантных функций, характеризующих гиперплоскость, используется обучающая выборка. Она также формируется из 2 групп водителей - Л и В. Следует подчеркнуть, что в группе Aфакторы риска
выясняются на момент, предшествующий началу заболевания, т.е. анамнестически.
Так как в нашем случае имеется всего два прогноза:А (неблагоприятный прогноз - возникновение заболевания)и ^(благоприятный прогноз - отсутствие заболевания), то проекция разделяющей линии выражается двумя классифицирующими функциями fA(xi), fB(xi).
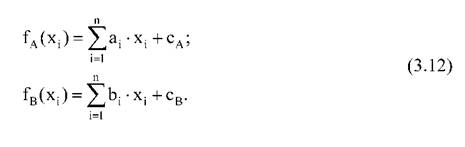
где xi- факторы риска, ai, bi- коэффициенты, сА, сВ- константы дискриминантных функций.
Вероятность того или иного прогноза трактуется как вероятность попадания (классификации) точки, представляющей исследуемого в пространстве факторов риска, в область, соответствующую данному прогнозу. Вероятность прогноза PL(xi),соответствующая наибольшей классифицирующейфункции
fL(xj), рассчитывается по формуле:
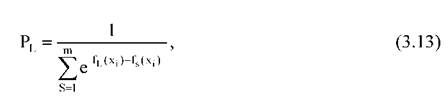
где е - основание натурального логарифма, S - индекс классифицирующей функции (в нашем случае - А или В).
В случае различения двух исходов PA(xi) = 1 - Pβ(xi).
Для оценки достоверности различения двух прогнозов при выбранном перечне факторов риска используется расстояние D2- Махаланобиса между
центрами областей Л и В. Его можно заменить χ2- статистикой Пирсона и сравнить с табличным значением.
Для построения прогностической модели целесообразно использовать не все факторы риска, а только те, которые дают наилучшие результаты классификации. Линейный дискриминантный анализ дает наилучшие результаты в том случае, когда характер распределения переменных нормальный (Гауссовский). Однако медицинские симптомы и признаки выражаются дискретными величинами, характер распределения которых отличается от нормального. Между тем, судя по многочисленным исследованиям, результаты классификации наблюдений оказываются достаточно хорошими. Это обусловлено тем, что вместо допущения нормальности распределения признаков можно принять менее жесткое требование - нормальность распределения самой дискриминантной функции.
Дискриминантный анализ позволил проследить характер влияния на результаты прогнозирования последовательного включения той или иной группы факторов риска.
С помощью такого приема можно оценить прогностическую ценность комплексов показателей.Схема алгоритма формирования бустинга на основе дискриминантного анализа представлена на рисунке 3.5. Сущность бустинга состоит в том, что обучающая выборка (множество .4Uβ) разбивается на ряд подмножеств, для каждого из которых определяется своя дискриминантная функция f iи свое пространство информативных признаков ИП i.
Структурная схема модуля бустинга, на основе которой принимается окончательное решение, представлена на рисунке 3.6. Агрегация решений слабых классификаторов f . осуществляется посредством обучаемой нейронной сети
NET.
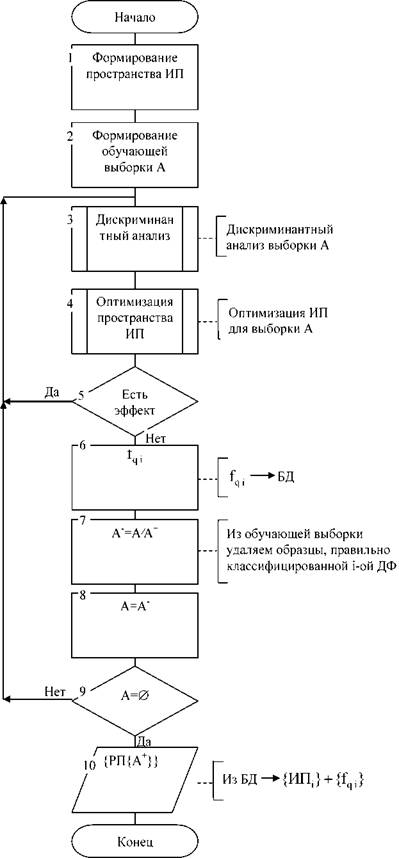
Рисунок 3.5 - Схема алгоритма бустинга
Алгоритм формирования бустинга работает следующим образом. Формируем множество А, в которое входят объекты обоих классов (А=АиВ). Строим первую дискриминантную функцию (первый слабый классификатор) блок 3 и в блоке 4 оптимизируем признаковое пространство. Признаковое пространство оптимизируем до тех пор, пока наблюдается улучшение качества классификации (блок 5).
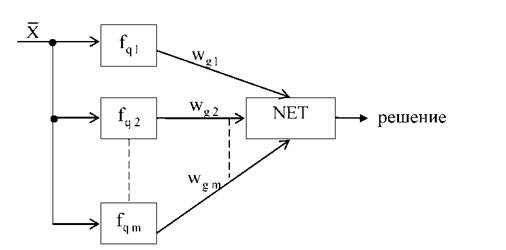
Рисунок 3.6 - Структурная схема модуля бустинга
Если качество классификации прекращает улучшаться, то переходим к построению следующей дискриминантной функции (слабому классификатору). Перед этим отправляем предыдущий слабый классификатор и соответствующее ему пространство информативных признаков в базу данных (блок 6), и получаем обучающую выборку для формирования следующего слабого классификатора путем исключения из текущейтех образцов, которые правильно классифицированы предыдущим слабым классификатором (блоки 7 и 8).
Этот процесс будет повторяться до тех пор, пока не будет правильно классифицированы все образцы исходной обучающей выборки.
3.3
Еще по теме Модуль принятия решений на основе бустинга:
- 3.3.1 Модуль принятия решений на основе экспертных оценок
- Модуль принятия решений по ишемическому риску на основе нечеткого логического вывода
- Экспериментальные исследования качества принятия решений модулей автоматизированной системы по прогнозированию ишемических рисков
- Разработка прототипов решающих модулей и моделей принятия решений для системы интеллектуальной поддержки прогнозирования профессиональной пригодности работников экстремальных профессий
- Автоматизирование системы принятия решений на основе электрических характеристик биологически активных точек
- Синтез гибридных нечетких решающих правил принятия решений на основе логики Л. Заде и Е. Шотрлифа
- Методы и алгоритмы принятия решений в медицинских системах интеллектуальной поддержки принятия решений
- 37. Психология принятия решения. Феномен риска в теории принятия решений.
- 3.5 Синтез нечетких правил принятия решений на основе идеологии метода групповые учета аргументов
- Структурно - функциональная модель принятия решений для дублирующих решениях и ассоциативном выборе
- Информация и принятие решений
- Технология принятия управленческого решения
- Коллективное принятие решений
- Выработка и принятие управленческих решений
- 3.3 Алгоритм управления процессами принятия решений