Структурно-функциональные решения организации виртуальных потоков для двух альтернативных выборок
Для двух альтернативных выборок необходимо построить две модели виртуальных потоков. Скрытые связи определяются аппроксимирующей функцией, построенной по данным, извлеченным из обучающей выборки (независимым переменным) и зависимым переменным, полученным посредством вероятностного программирования [14, 67].
Если такая аппроксимирующая функция будет построена, то по данным неизвестного образца может быть найден дополнительный признак как функция этих входных данных.Полагаем, что неизвестный образец характеризуется вектором наблюдаемых информативных признаком Xс компонентами x1, x2,...,xm.Необходимо получить функциональную зависимость латентной переменной Yот наблюдаемого вектора X, то есть

полагая, что присутствие на входе классифицирующей модели этого информативного признака улучшит качество классификации.
Модель нейросетевой структуры с виртуальным потоком показана на
рисунке 3.4 [9].
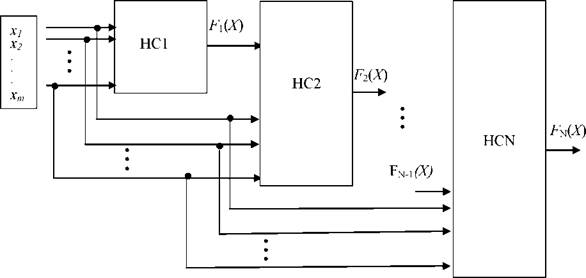
Рисунок 3.4 - Структура нейросетевой модели с виртуальными потоками
При этом в обучающую выборку для аппроксиматоров входят не только экспериментальные данные, полученные на соответствующем интервале наблюдения, но и данные, полученные в результате имитационного моделирования на предшествующей нейросетевой модели. То есть, каждый нейросетевой модуль (НС на рисунок 3.4) в этой модели, кроме первого и последнего, является не только анализатором латентного параметра X, но источником данных для настройки параметров (обучения) последующего модуля.
Таким образом, необходимо решить задачу, состоящую в обнаружении и моделировании некоторой закономерности (3.7). Проблемы, возникающие при восстановлении функциональных зависимостей в условиях коротких выборок, являются типичными проблемами, возникающими при применении индуктивных методов, и существенно отличаются от классических проблем восстановления по выборкам большого объема.
Особенность состоит в том, что при ограничении объема выборки качество восстановления зависит не только от качества аппроксимации в точках yj∙, но еще и от таких факторов, как сложность аппроксимирующей функции и размерности пространства т.Эта особенность заставляет сосредоточить внимание на правильном
соотнесении сложности приближающей функции с объемом обучающей выборки, так как имеющейся информации может не хватить даже для восстановления функции только в точках yj.Тем более этой информации может не хватить для удовлетворительного восстановления в любой точке ее существования.
Среди немногих методов, в которых особое внимание уделяется поиску такого соотнесения, выделяются метод группового учета аргументов (МГУА) [9]. Рассмотрим метод синтеза модели оптимальной сложности более подробно.
В качестве функциональной зависимости (3.7) используем полином Колмогорова-Габора [9]:
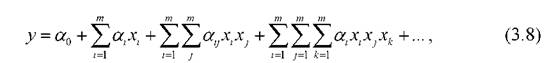
так как с помощью такого полинома можно добиться достаточно точной аппроксимации любой дифференцируемой функции F.
Эта сложная зависимость заменяется множеством простых функций:

где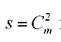 причем функция fповсюду одинакова.
причем функция fповсюду одинакова.
Очень часто в качестве функции fвыбираются простые зависимости
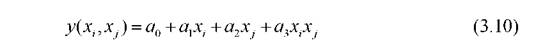
или
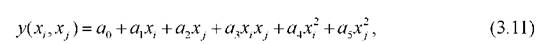
связывающие только две переменные. Коэффициент этих зависимостей можно определить по МНК, имея соответственно 4 или 6 точек наблюдений в обучающей последовательности. Среди моделей первого ряда выбираются несколько, например S*наилучших, показавших хорошие результаты на проверочной выборке.
Среди отобранных моделей остаются только те, которые «впитали» в себя нечто большее, чем хорошая аппроксимация в узлах интерполяции; они
«угадывают» поведение функции (3.8) в области, не охваченной экспериментом. Во втором ряду алгоритма полученные на обучающей выборке значения Уі ’ соответствующие отобранным моделям, рассматриваются в качестве аргументов нового ряда:
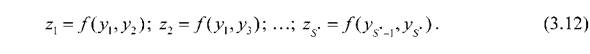
Здесь функция fостаются прежними и соответствуют соотношениям (3.10) или (3.11), но аргументами этих функций выступают переменные у. . Коэффициенты новых моделей (3.12) находятся по МНК на точках той же обучающей последовательности. Новые модели проверяются на точках проверочной последовательности, и среди них выбирается S*наилучших, которые используются в качестве аргументов следующего третьего ряда и т.д. Сложность полиномов возрастает от ряда к ряду [14, 44, 45, 48].
Среди множества МГУА - моделей выбираем Lнаилучших, которые могут быть представлены в виде множества

где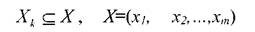 - множество информативных признаков
- множество информативных признаков
используемых решающими модулями;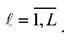
На рисунок 3.5 представлена обобщенная структурная схема классифицирующего модуля, предназначенного для работы с дополненным на основе МГУА - моделей пространством информативных признаков.
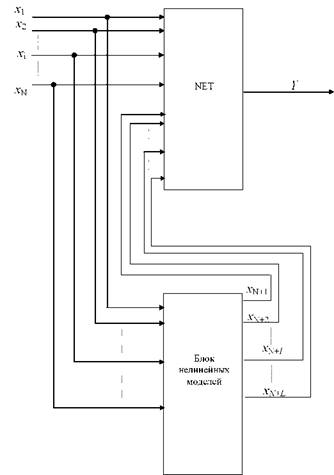
Рисунок 3.5 - Структурная схема классификатора, предназначенного для работы с виртуальными потоками, полученными на основе МГУА - моделей исходного пространства информативных признаков
Рассмотрим метод формирования множества (3.13). Метод должен синтезировать множество аппроксимирующих связей между элементами входного вектора Xи позволить выбрать из этого множества Lфункциональных связей, которые формируют Lдополнительных (виртуальных) признаков, включение которых во входной вектор приводит к повышению качества классификации решающего модуля.
В случае вырождения нелинейных моделей в линейные многомерные аппроксиматоры блок нелинейных моделей (рисунок 3.5) включает множество пар (в случае двухальтернативной классификации) классифицирующих функций (аппроксиматоров), каждый из которых выдает число, соответствующее состоянию входного вектора. При необходимости, эти два числа (а и b,) могут
быть агрегированы в одно посредством одного из следующей группы агрегаторов:
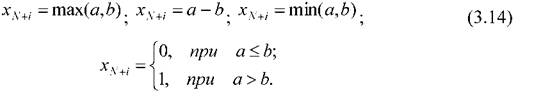
При этом необходимо учитывать, что соответствующие выходы блоков, моделирующие корреляционные связи исходных информативных признаков, могут быть как двухкомпонентными векторами, так и скалярами, в зависимости от наличия в моделирующих модулях агрегирующих блоков вида (3.8).
Включение в множество моделей очередной, ((+1) -й, модели, осуществляется по рекуррентной схеме, представленной на рисунке 3.4. Эта схема позволяет оценить вклад в показатели качества принятия решений (£+1) -го дополнительного информативного признака при наличии (Y)дополнительных признаков. В общем случае, для построения модели рисунок 3.5 привлекаются алгоритмы эволюционного типа («жадные» алгоритмы) [9, 14].
Блок нелинейных моделей ВП составляет основу классифицирующего модуля рисунок 3.5. Блок нелинейных моделей состоит из двух слоев. Первый слой формирует множество моделей Y. Для каждого ВП посредством МГУА - моделирования получено свое подмножество моделей
Каждое подмножество {zj}., j = 1.. Ki, где Ki- число МГУА - моделей для i-го ВП, описывает взаимное влияние реальных ИП (реальных потоков) друг на друга и на ВП в системе простых комбинаций реальных и виртуальных потов. Каждый блок модели ВП (второй слой модели) является МГУА-НС, на входы которой поступают полученные путем МГУА-моделирования модели, включающие множество Xреальных и виртуальных потоков [14, 44, 45, 67].
Структурная схема i-го блока модели виртуального потока представлена на рисунок 3.6.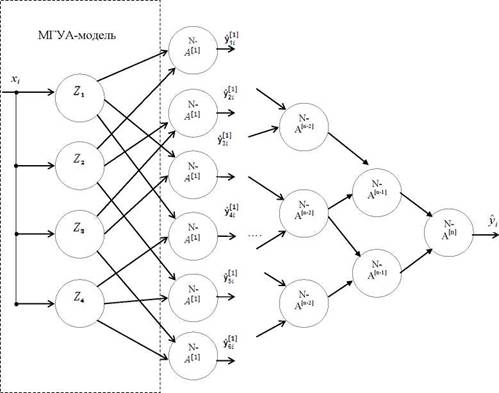
Рисунок 3.6 - Структурная схема i-й нелинейной модели на основе МГУА - моделирования
В качестве примера в ней использованы четыре МГУА - модели виртуального потока .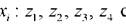 ; нелинейными адалинами (N-A).
; нелинейными адалинами (N-A).
МГУА - сеть имеет переменную структуру, которая может изменяться в процессе обучения. Каждый нейрон сети - N-адалина представляет собой адаптивный линейный ассоциатор с двумя входами zgи zhи нелинейным процессором, образованным тремя блоками умножения, и вычисляет квадратичную комбинацию входов вида 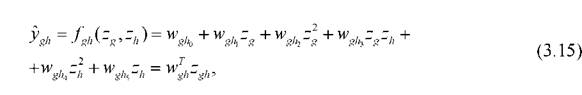 где
где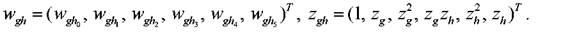
Обучения МГУА - модели ВП состоит в формировании структуры НС (рисунок 3.6), начиная с первого скрытого слоя. Настройка синаптических весов
осуществляется независимо для каждого нелинейной адалины. Число скрытых слоев наращивается до тех пор, пока не будет достигнута заданная точность прогнозирования. Количество нейронов первого скрытого слоя НС определяется количеством К МГУА - моделей. и не превышает значение К(К-1)/2 - количества сочетаний из К по 2.
После обучения НС посредством любого из известных алгоритмов обучение [75, 104, 113] оценивается точность моделирования и формируется группа нейронов, дающих ошибку ниже некоторого априорно заданного порога. Выходы этой группы y[1]являются входами НС рисунок 3.6 [14, 44, 45, 67].
3.2
Еще по теме Структурно-функциональные решения организации виртуальных потоков для двух альтернативных выборок:
- Структурно - функциональная модель принятия решений для дублирующих решениях и ассоциативном выборе
- 4.1 Структурно-функциональная организация интеллектуальной системы для прогнозирования сердечно-сосудистого риска
- Структурная организация системы поддержки принятия решений для прогнозирования профессиональной пригодности работников экстремальных профессий
- Гибридные решающие модули для формирования виртуальных потоков
- 4.2 Метод синтеза виртуального потока для нейронной сети прямого распространения
- 4.1 Функционально-структурная организация ИАСППР
- 3 Методы и модели структурно - функциональных решений при прогнозировании ишемических рисков
- 4. Разработка современной структурно-функциональной организации СПЭБ на основе модульного принципа укомплектования.
- Методы и модели построения виртуальных потоков
- Разработка и исследование структурно-архитектурных решений для интеллектуальной системы прогнозирования повторного инфаркта миокарда
- Изменения структурно-функциональной организации нервной ткани в постнатальном онтогенезе после пренатальной гипоксии
- Структурные и архитектурные решения для мультиагентных интеллектуальных систем прогнозирования инсультов
- Виртуальные потоки на основе биоимпедансных исследований