Статистические методы обработки полученных данных
Статистическая обработка материала диссертационной работы
произведена на персональном компьютере IBM PC/AT - Pentium IV. в среде Windows 2000 с применением пакета компьютерных программ и электронных таблиц (Excel, Fox Pro, Open Access, Paradox), а также с использованием статистической библиотеки программ «Statistica».
Методика расчета подбиралась в соответствии с рекомендациями следующих авторов: Дж. Поллард, Дж. Гласс, Дж. Стенли, с использованием методов описательной статистики, корреляционного анализа. Корреляционный анализ включал в себя методы Пирсона, Спирмена, а также анализ дихотомий Кертена, в зависимости от шкал исследуемых величин.Fxy =
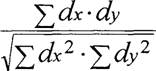
Достоверность вычисленного коэффициента корреляции оценивали при помощи средней ошибки (шг) и критерия t по ниже приведенным формулам:
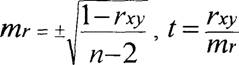
При проверке гипотез для сравниваемых выборок применялись дисперсионный анализ с методами множественных сравнений Шеффе и Тьюки, а также T - критерий Стьюдента для парных сравнений.
Оценка значимости факторов риска определялась с помощью определения показателя относительного риска и границ его возможных колебаний - OP (Сі).
Для подтверждения неслучайности различий определялись доверительные границы (Ci) относительного риска по формуле, предложенной Haldane (1970 г.)
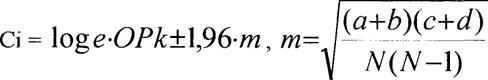
где N- сумма всех наблюдений в основной и контрольной группах.
Метод расчета заключался в вычислении логарифмов доверительных интервалов так называемого корригированного относительного риска OPk , после чего следует переход к нормальной шкале.
OPk (относительный риск, корригированный) вычислялся нами по формуле:
(a+0,5)(d+0,5)
(Ъ+0,5)(с+0,5)
Для того чтобы выявить степень влияния фактора в целом и отдельных его составляющих, мы воспользовались методикой неоднородной последовательной процедуры распознавания - НПП, которая позволяет определить индивидуальный риск возникновения патологии, зависящей от всего комплекса факторов риска с учетом значимости каждого. Для этого каждый отобранный фактор мы подразделяли на определенное число диапазонов (градаций) признака, подсчитывая частоту каждого из них в группах, работающих на заводе «Тольяттиазот» и заводе «Тольяттитрансформатор», определяли диагностический коэффициент (ДК) для каждого диапазона по формуле:
Pi
Dk = IOlg^i
Pl
Где Р] и P2 - частота диапазона признака у женщин сравниваемых групп, и информативность (J) по формуле:
J = IOlg^i -0,5{P\-Pi)
В ряде случаев, продиктованных типом распределения исследуемых величин, обработка данных производилась методами непараметрической статистики, среди них: Вилкинсона - Манна-Уитни - критерий различий в средних тенденциях для независимых выборок; серийный критерий Вальда - Вольфовица; точный метод Фишера для четырехпольных таблиц, метод углового преобразования Фишера и метод Z статистики для оценки в совокупности; кси-квадрат критерий для анализа таблиц сопряженности признаков.
Еще по теме Статистические методы обработки полученных данных:
- Методы статистической обработки полученных данных
- Статистическая обработка полученных данных
- Статистическая обработка полученных данных
- Статистическая обработка полученных данных.
- 2.3 Статистическая обработка полученных данных
- Методы статистической обработки данных
- Методы статистической обработки данных.
- 3.2.11 Методы статистического анализа полученных данных
- Методы научного анализа и статистической обработки полученных результатов
- 2.7 Методы статистического анализа полученных данных
- 2.3. Методы статистической обработки полученных в исследовании результатов
- Методы статистической обработки экспериментальных данных
- 2.6. Математические методы Статистическая обработка цифровых данных
- Статистическая обработка данных
- 2.3. Статистическая обработка полученных результатов.
- Статистическая обработка данных
- Статистическая обработка полученных результатов
- Статистическая обработка данных