Метод синтеза решающего модуля для классификации текущего состояния сложной системы в пространстве «резерв СФЕ - ресурс СФЕ»
Как было установлено выше, переход сложной системы из одного функционального состояния в другое связан с изменением числа активных СФЕ, которое может быть осуществлено как за счет «вибрирующих» СФЕ, так и за счет «включения в работу» невозбужденных СФЕ.
Относительноечисло активизированных СФЕ зависит от параметров акции (действия) а и может быть описано одной из известных математических моделей, например, логистической моделью. Для описания текущего состояния системы при этом используют две латентные переменные: функциональный резерв СФЕ и функциональный ресурс СФЕ.
На основе предложенных моделей может быть построен классификатор, посредством которого ЛПР будет выбирать соответствующую акцию (действие), позволяющую перевести систему из одного ФС в другое (желаемое) состояние.
Путем «размытия» третьего класса СФЕ, получаем «стробоскопическую» модель системы, представленную на рисунке 2.6, которая позволяет использовать для анализа и управления состоянием системы нечеткую логику принятия решений [58, 61, 190].
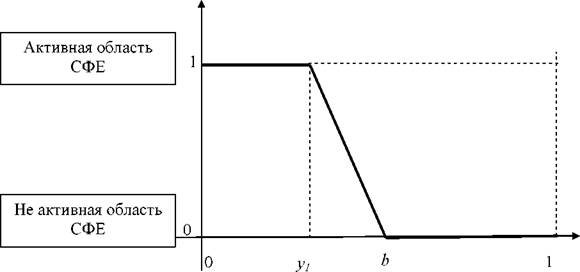
Рисунок 2.6 - Модель поведения ФСС при нечетком описании СФЕ третьего класса
Согласно этой модели, СФЕ, находящиеся в «вибрирующем» состоянии, определяются отрезком на оси абсцисс, заключенном между точками y1и b,и их состояние может описываться промежуточными значениями, заключенными между нулем и единицей.
Решающий модуль для определения состояния сложной системы в выбранном пространстве признаков не может быть обучаемым классификатором, так как координаты такого пространства нельзя измерить непосредственно, а также сформировать обучающую выборку с априорно известными значениями признаков. Наиболее перспективным способом решения поставленной задачи является построение экспертной системы с набором «свидетельств», которые характеризовали бы принадлежность объекта наблюдения к определенному нечеткому множеству.
Причем различные свидетельства относятся к компетенции различных экспертов. В конечном счете, каждый эксперт анализирует некоторое множество косвенных признаков (индикаторных переменных) и на основе их анализа делает заключение о принадлежности объекта наблюдения (латентной переменной) к некоторому интервалу на соответствующей шкале. Так как указать четкие интервалы на этой шкале не представляется возможным, потому что они устанавливаются экспертами, то такую интервальную шкалу назовем нечеткой.Нечёткое множество А в полном пространстве X определяется через функцию принадлежности (membership function): μ: X→ [θ,1J Величина μ (x), x∈X интерпретируется как субъективная оценка степени принадлежности элемента xк нечёткому множеству A.
Носителем нечёткого множества или несущим множеством А называется чёткое подмножество полного пространства X, на котором значение μ (x) положительно: σ(A) = {x∈X∣ μ (x) >θ}
Нечёткими F-множествами называют совокупность всех нечётких подмножеств F(X)произвольного базового множества X а их функции принадлежности - F-функциями. Как правило, под μпонимают сужение функции принадлежности со всего X на σ(A), поэтому F- множества обычно задают функцией принадлежности и несущим множеством A = (μιA (x ),σ(A)}.
Нечёткая переменная - это объект предметной области, характеризуемый тройкой {N, X, R(N, х)}, где N- название переменной, X - универсальное множество (полное пространство наблюдений) с базовой переменной X, R(N, х)? F (X ) - нечёткое F-множество, задающее ограничения на значения переменной х, обусловленные её названием N [111, 141, 161, 231, 232].
Лингвистическая переменная - это нечёткая переменная, значениями которой являются другие нечёткие переменные: слова или предложения естественного или формального языка [111].
Нечёткая шкала (fuzzy scale) (рисунок 2.7) - это упорядоченная совокупность S'нечётких переменных Ai,определенных своими F- функциями, значения из которой может принимать некоторая лингвистическая переменная 5
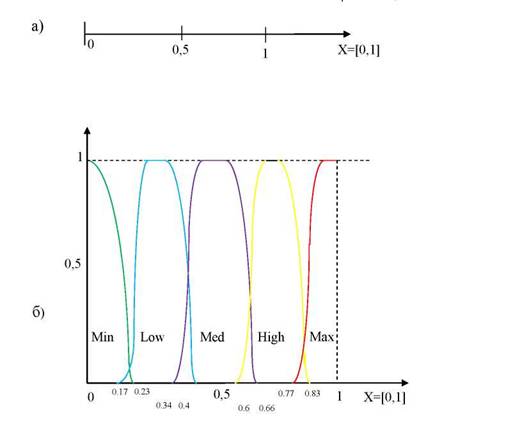
Рисунок 2.7 - Четкая шкала интервального типа (а) и нечеткая шкала интервального типа (б)
Фиксация значения 5 = Д для некоторого свойства означает, что оно оценивается лингвистической переменной 5и имеет значение Ai.Для задания шкалы Sнеобходимо определить все нечёткие переменные Ai,указать их функции принадлежности и несущие множества [111].
Для четкой шкалы Spвыбирается множество действительных чисел из отрезка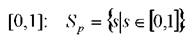 Для нечёткой шкалы Sfвыбирается
Для нечёткой шкалы Sfвыбирается
универсальная шкала лингвистических переменных, например, как показано на рисунке 2.7 б: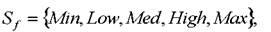 где лингвистические
где лингвистические
переменные задаются нечёткими множествами:
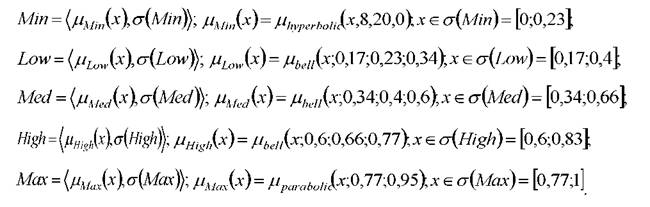
Функцией дефаззификации (defuzzification function) для нечеткого множества заданного своей функцией принадлежности
заданного своей функцией принадлежности
μA(х), называется любая функция Defuz(LiA (x)) , возвращающая чёткое значение х∈X, «характерное» для А. Например, для отображения Defuz чёткое значение нечёткого уровня А вычисляется по методу центра тяжести [114]: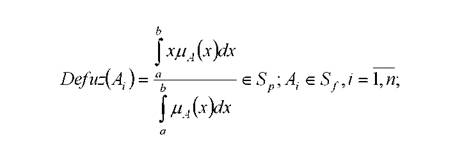
Таким образом, чтобы разработать метод синтеза решающего модуля для измерения латентных переменных на нечетких шкалах, необходима концептуальная модель нечеткого шкалирования. На рисунке 2.8 представлена концептуальная модель нечеткого шкалирования.
86
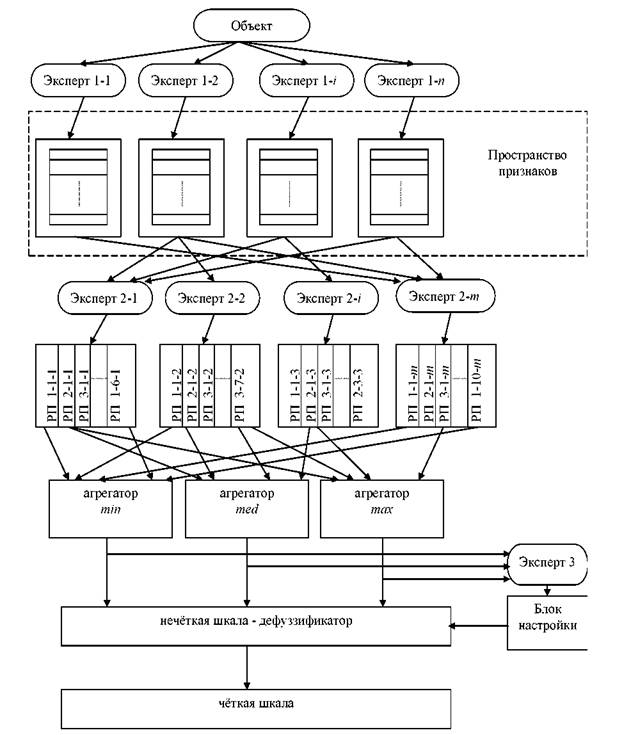
Рисунок 2.8 - Концептуальная модель нечёткого шкалирования
Концептуальная модель основана на формировании подмножеств информативных признаков - индикаторных переменных, выбор и анализ которых основан на экспертном оценивании.
Идея измерения латентных переменных основана на опросе экспертов с последующим усреднением их мнений, что позволяет получить некоторую точку на интервальной шкале [3, 14, 15, 66]. При этом индикаторные
переменные получают посредством опросника или синтезируются согласно методам, описанным в [154, 163, 171], причем грань между респондентом и экспертом стирается, так как оцениваться может не только объект через опросник (метод), но и сам опросник (метод).
В концептуальной модели нечеткого шкалирования, представленной на рисунке 2.8, выделено два уровня экспертного оценивания. На первом уровне исследуемый объект характеризуется некоторыми информационными "срезами". Каждый информационный срез представлен подмножеством косвенных, по отношению к искомой латентной переменной, признаков. Эксперты второго уровня анализируют эти подмножества признаков и выносят решение о принадлежности исследуемого объекта или его свойства к нечеткому интервалу на порядковой шкале. Такие решения представляются в виде нечетких решающих правил продукционного типа. Решающие правила могут использовать, как только одно подмножество косвенных признаков, так и произвольную комбинацию признаков, взятых из нескольких подмножеств. Обычно решающие правила, которые в данном случае выступают в качестве "слабых" классификаторов, строятся по одному множеству косвенных признаков и отражают мнения экспертов о состоянии сложной динамической системе, полученные по результатам анализа одного множества косвенных признаков [171].
Ситуация может измениться, когда на первом экспертном уровне осуществляется локальное шкалирование на четких или нечетких шкалах. Локальное шкалирование состоит в том, что по подмножеству косвенных признаков получают четкую или нечеткую шкалу для локальной (локальных) латентных или не латентных переменных. В этом случае решающие правила могут строится экспертами второго уровня по различным подмножествам информативных признаков с учетом их трансформации в локальные переменные.
Решающие правила на втором уровне формируются по разным подмножествам признаков разными экспертами. Каждое нечеткое решающее
правило определяет уверенность или принадлежность данной латентной переменной к данному нечеткому множеству нечеткой шкалы. На рисунке 2.8 в целях компактности представления концептуальной модели выбрано только три нечетких множества, обозначенные термами min, med, max.
На уровне концептуальной модели, представленном агрегаторами, осуществляется агрегация нечетких решающих правил для каждого терма.
Известно множество методов и алгоритмов построения агрегаторов нечетких решающих правил [60, 76, 82]. Основным недостатком этих методов, на наш взгляд, является то, что авторы не пытаются обосновать свои подходы к агрегации нечетких решающих правил и не представляют рабочих методов, позволяющих верифицировать полученный результат. Поэтому разработчику остается только констатировать качество работы полученной модели и при отрицательном результате натурных испытаний внести соответствующие изменения в модель. Для нечетких моделей, связанных с долгосрочным прогнозом, такая возможность отсутствует, поэтому при разработке метода агрегации будем ориентироваться на хорошо зарекомендовавшие себя методы агрегации, используемые в системах медицинского прогнозирования.Сформировав пространство информативных признаков для каждого подмножества косвенных информативных признаков, можем приступить к построению «слабых» классификаторов для определения искомых латентных переменных.
В каждом подмножестве косвенных признаков строятся «слабые» классификаторы, принимающие решения по соответствующему подмножеству косвенных информативных признаков. Для агрегирования решений «слабых» классификаторов используются «сильные» классификаторы агрегаторы, которые агрегируют решения «слабых» классификаторов.
За основу построения агрегатора взята схема Шортлиффа, описанная в [108]. Основу этой модели составляют правила продукционного типа (ПП)
89
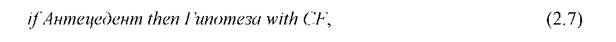
где if, then, with -ключевые слова-разделители; Антецедент - формула, построенная из факторов или гипотез с помощью операций конъюнкции, дизъюнкции или отрицания при этом операнды в этой формуле лежат в диапазоне 0...1; конструкция «Гипотеза with CF» - консеквент ИИ R; Гипотеза ИИ R - одна из гипотез решающего модуля; CF- коэффициент уверенности ИИ R.
В модели Шортлиффа набор операций и отношений над операциями фиксирован (операции осуществляются только над двумя операндами):

1ри этом полагаем, что косвенные признаки только подтверждают (не опровергают) гипотезу о принадлежности латентной переменной к нечеткому интервалу.
В 11 последовательно включаются косвенные признаки, причем не важно, в каком порядке, и экспериментально оцениваются коэффициенты уверенности НИ при наличии заданного числа косвенных признаков
(объединенных по and). Чем больше косвенных признаков присутствует в НИ, тем выше коэффициент уверенности этого решающего правила.
На рисунке 2.9 представлена схема обработки i-го НИ. Схема состоит из четырех секторов. В секторе А вычисляется антецедент i-го НИ.
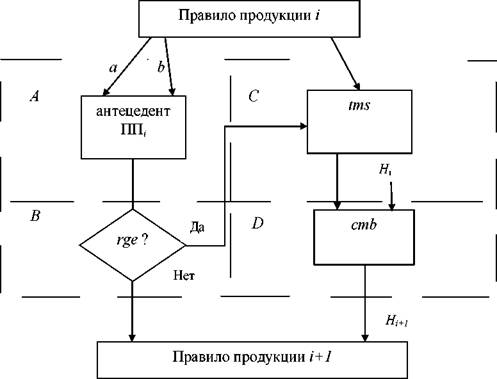
Рисунок 2.9 - Обработка i-го продукционного правила
В секторе В сравнивается по А данным результат с пороговым значением. Пороговое значение подбирается эмпирически в каждом подмножестве косвенных признаков и зависит от максимального значения функции принадлежности латентной переменной по данному подмножеству к данному терму нечеткой шкалы. Если результат меньше порогового, то данное 11 не участвует в формировании итогового коэффициента уверенности данного «сильного» классификатора, то есть не приводит к изменению гипотезы H. Если результат больше порогового, то его нормируют (взвешивают) в секторе С в соответствии с коэффициентом уверенности этого 11 посредством операции tms. В секторе Dпринимают гипотезу Hωi,в соответствии с (i+1)-м ИН посредством формулы (2.11).
На рисунке 2.10 представлена схема алгоритма работы «сильного»
классификатора.
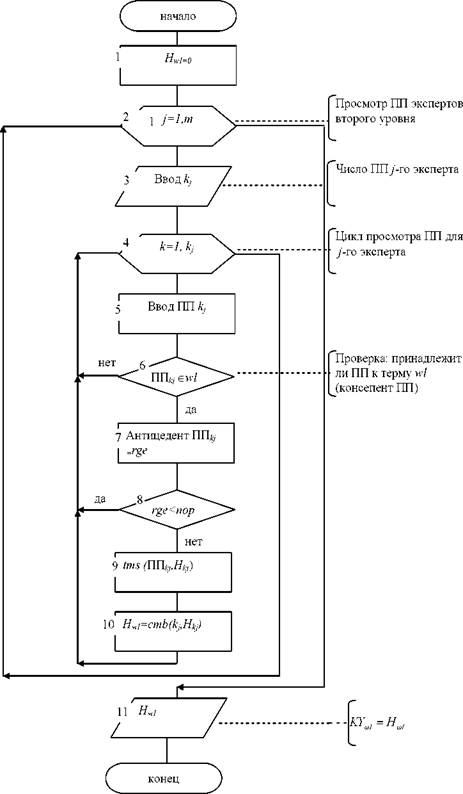
Рисунок 2.10 - Схема алгоритма работы «сильного» классификатора для терма H
В блоке 1 осуществляется подготовка итерационного процесса накопления свидетельств в пользу гипотезы Hcrf. В блоке 2 осуществляется цикл просмотра правил продукций по m экспертам второго уровня. В блоке 3 осуществляется ввод количества правил продукции у ткущего эксперта второго уровня для гипотезы H.
В блоке 4 организуется цикл просмотра правил продукции по текущему эксперту второго уровня для гипотезы H.
Блок 5 осуществляет ввод текущего правила продукции эксперта второго уровня, а в блоке 6 осуществляется проверка принадлежности этого правила продукции гипотезе Hωf.
В блоке 7 вычисляется антецедент решающего правила согласно (2.2), в блоке 8 решающее правило активируется в зависимости от результата сравнения с порогом. Если решающее правило активировано, то осуществляется взвешивание его антецедента в блоке 9 в зависимости от его коэффициента уверенности h∖. . В блоке 10 осуществляется вычисление текущего значения коэффициента уверенности в гипотезе по данному «слабому» классификатора, а в блоке 11 выводится окончательное значение коэффициента уверенности по данному «слабому» классификатору.
Сильные классификаторы согласно концептуальной модели рисунка 2.8 объединяются в нечеткую шкалу посредством дефуззификатора. Окончательная задача состоит в том, чтобы по нечеткой шкале получить точку, соответствующую ресурсу или резерву исследуемой системе. Нечеткая шкала должна быть разбита на нечеткие множества. Так как априорных данных об этой шкале нет, то есть она представляет собой некий конструкт, то на ней произвольно введем три нечетких множества посредством трех термов: «высокий», «средний», «низкий», которые разбивают шкалу [0,1] на три пересекающихся подмножества (рисунок 2.11).
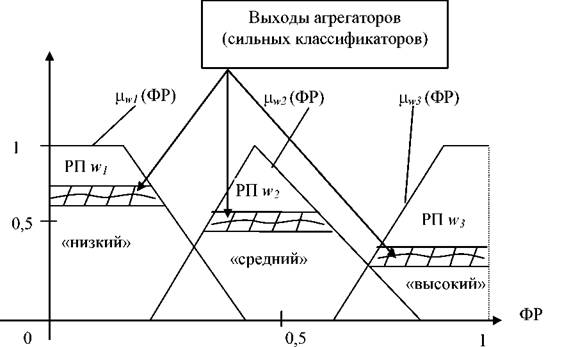
Рисунок 2.11 - Технология измерения ФР на нечеткой интервальной
шкале
Принадлежность искомой точки к этим подмножествам определяется посредством набора нечетких продукций и правил их агрегации (посредством сильных классификаторов). После определения принадлежности объекта к каждому из этих подмножеств посредством дифуззификации определяем окончательную (четкую) координату искомой точки на измерительной шкале. Окончательный этап этого процесса иллюстрирует рисунок 2.11.
Для того чтобы реализовать технологию измерения ФР, представленную на рисунке 2.11, необходимо сформировать множество решающих правил для определения значений функций принадлежности для каждого из термов w1, w2 , w3.
Так как в формируемом признаковом пространстве могут быть представлены не все релевантные информативные признаки или сегменты, то было предложено ввести дополнительный «слабый» псевдо классификатор, который мы назовем D- классификатором. Псевдо классификатор
генерирует на выходе число в диапазоне от 0 до 1, значение которого подбирается для каждого объекта обучающей выборки таким образом, чтобы минимизировать ошибку «сильного» классификатора при его обучении. На схеме концептуальной модели это прерогатива Эксперта 3. Псевдо классификатор ничего не дает при классификации неизвестного образца, но позволяет перераспределить соотношения весов других, не фиктивных «слабых» классификаторов, с учетом влияния не наблюдаемого фактора.
Настройку решающего модуля осуществляем в два этапа. «Слабые» классификаторы формируются на основе экспертных оценок. После формирования «слабых» классификаторов формируется сильный классификатор посредством обучения по результатам опросов работников МЧС с заболеваниями, включенными в задачи исследования.
2.4
Еще по теме Метод синтеза решающего модуля для классификации текущего состояния сложной системы в пространстве «резерв СФЕ - ресурс СФЕ»:
- Синтез модели ФСС на основе СФЕ для определения эффекта экстремальных воздействий
- Метод оценки функционального состояния и функционального резерва организма и его систем в условиях действия электромагнитных факторов.
- Методология синтеза коллективов решающих правил для оценки и управления состоянием живых систем на основе технологий мягких вычислений
- Структурный анализ и синтез признакового пространства для математических моделей прогнозирования и развития ишемии сердца
- Метод классификации функционального состояния сердечно-сосудистой системы по предикторам синхронности системных ритмов, определяемым по монокардиосигналу
- Методы исследования функционального состояния и адаптационных резервов в процессе учебной деятельности студенток
- Синтез итоговой модели классификации для выявления микроциркуляторных нарушений при ревматических заболеваниях
- Разработка прототипов решающих модулей и моделей принятия решений для системы интеллектуальной поддержки прогнозирования профессиональной пригодности работников экстремальных профессий
- Формирование пространства информативных признаков для интеллектуальной системы прогнозирования артериальной гипертензии у водителей транспортных средств
- 4.2 Метод синтеза виртуального потока для нейронной сети прямого распространения
- Учет текущего состояния организма в организации оздоровительной физкультуры
- 52. Сложные нарушения развития. Подходы к классификации. Психическое развитие при сложных нарушениях