Методы и модели четкого и нечеткого прогнозирования
Одной из основных задач диссертационного исследования является прогнозирование появления и развития ГНК, которая, в общем виде, может быть решена методами четкого и нечеткого прогнозирования [179].
Под прогнозом понимают процесс научного, основанного на системе общепринятых причинно-следственных связей и закономерностей, выявления состояния и вероятных путей развития явлений и процессов. Соответственно, прогнозирование - это «процесс предвидения, предсказания тенденций и перспектив дальнейшего развития тех или иных объектов и их будущего состояния на основе знания закономерностей развития их в прошлом и в настоящее время». Прогнозирование предполагает оценить показатели, которые характеризуют эти явления и процессы для будущего [52]. Распространение прогнозирования, в основном, направлено на процессы, управлять которыми необходимо в момент выработки прогноза или возможно в весьма малом диапазоне, или совсем невозможно, или оно возможно, но требует учета действия таких факторов, влияние которых не может быть полностью или однозначно определено.
Прогноз - это результат прогнозирования, который выражен в словесной, математической, графической или другой форме научно обоснованного суждения о возможных состояниях объекта в будущем и/или об альтернативных путях и сроках достижений этих состояний.
Основные методы прогнозирования можно выделить в четыре крупные группы [13, 42, 56]:
- методы экспертных оценок;
- методы экстраполяции трендов;
- методы регрессионного анализа;
- методы экономико-математического моделирования.
Рассмотрим несколько методов прогнозирования, которые находят применение в медицинской практике [153].
Одним из распространённых методов краткосрочного прогнозирования (1-3 временных периода), является экстраполяция, заключающаяся в продлении предыдущих закономерностей на будущее. Применение экстраполяции для прогнозирования базируется на следующем:
- развитие исследуемого явления в целом описывается плавной кривой;
- общая тенденция развития явления в прошлом и настоящем не претерпит серьезных изменений в будущем.
Одним из распространённых методов краткосрочного прогнозирования является метод среднего уровня ряда. Для этого метода прогнозируемый уровень изучаемой величины принимают равным среднему значению уровней ряда этой величины в прошлом. Данный метод используют, если средний уровень не имеет тенденции к изменению, или это изменение:
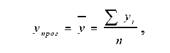
где упрог - прогнозируемый уровень изучаемой величины; yi- значение і-го уровня; n - база прогноза.
Отрезок динамического ряда, который охвачен наблюдением, можно определить, как значение выборок, а значит, полученный прогноз будет выборочным, для него можно указать доверительный интервал:

критерий Стъюдента для заданного уровня значимости и числа степеней свободы (n-1).
Метод скользящих средних - метод прогнозирования для краткосрочного периода, который основан на процедуре сглаживания уровней изучаемой
19 величины (фильтрации). Зачастую используются линейные фильтры сглаживания с интервалом m, т.е.

доверительный интервал

критерий Стъюдента для заданного уровня значимости и числа степеней свободы (n-1).
Метод экспоненциального сглаживания - метод, для которого в процессе выравнивания каждого уровня используются значения предыдущих уровней, взятых с определенным весом. По мере удаления от какого-то уровня вес этого наблюдения уменьшается. Сглаженное значение уровня на момент времени t определяется по формуле:
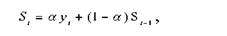
где St- текущее сглаженное значение; yt- текущее значение исходного ряда; St - 1
- предыдущее сглаженное значение; α - сглаживающая параметр.
Soберется равным среднему арифметическому нескольких первых значений ряда.
Для расчета α берется следующая формула
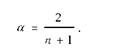
Для выбора α не существует единого мнения, эта задача оптимизации модели пока еще не решена. Некоторыми источниками литературы рекомендовано выбирать 0,1 ≤ α ≤ 0,3.
Формула для расчета прогноза:
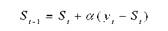
Доверительный интервал рассчитывается следующим образом:
20
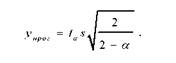
Использование современных пакетов прикладных программ позволяет находить аналитические выражения, описывающие временные тренды. Тренд экстраполируемого явления - это основная тенденция временного ряда, в некоторой мере свободная от случайных воздействий.
Прогнозирование заключается в определении вида экстраполирующей функции y=f(t), которая определяет зависимость изучаемой величины от времени на основе исходных наблюдаемых данных. Первым этапом является выбор оптимального вида функции, дающей наилучшее описание тренда. Основные используемые зависимости:
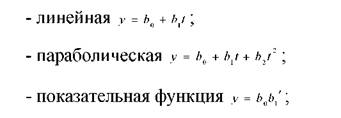
Метод регрессионного анализа решает проблемы нахождения коэффициентов линейной функции и ее прогноз.
Если кривая, описывающая тренд, имеет нелинейный характер, то задача оценки функции y=f(t) усложняется, и в этом случае необходимо привлечь к анализу специалистов по биостатистике и воспользоваться компьютерными программами по статистической обработке данных [30, 31].
В основном временной ряд представляется сложной кривой, которую можно определить, как сумму или произведение трендовой, сезонной, циклической и случайной компонент.
Тренд представлен плавным изменением процесса во времени и обусловлен действием долговременных факторов.
Сезонный эффект связан с наличием факторов, которые действуют с периодичностью, известной заранее (например, времена года, лунные циклы). Циклическая компонента описывает длительные периоды относительного подъема и спада, состоит из циклов переменной длительности и амплитуды (например, некоторые эпидемии имеют длительныйциклический характер). Случайная составляющая ряда отражает воздействие многочисленных случайных факторов и может иметь разнообразную структуру.
В условиях плохой формализации может быть использован метод экспертного прогнозирования. В экспертном прогнозировании выделяется несколько главных этапов [13, 14].
1. Подготовка к разработке прогноза.
2. Анализ ретроспективной информации, внутренних и внешних условий.
3. Определение наиболее вероятных вариантов развития внутренних и внешних условий.
4. Проведение экспертизы.
5. Разработка альтернативных вариантов.
6. Априорная и апостериорная оценка качества прогноза.
7. Контроль хода реализации прогноза и корректировка прогноза.
Во время подготовки к разработке прогноза необходимо решить следующие задачи: подготовить организационное обеспечение разработки прогноза; сформулировать задание на прогноз; сформулировать рабочую и аналитическую группы сопровождения; сформировать экспертную комиссию; подготовить методическое обеспечение разработки прогноза; подготовить информационную базу для проведения прогноза; подготовить компьютерное сопровождение разработки прогноза [1, 2, 3, 4, 5, 6, 12, 15].
После принятых решений о разработке прогноза назначаются исполнители для этой разработки, которые поручаются за организационное обеспечение разработки прогноза. Также эти люди обеспечивают его методическое и информационное сопровождение [17, 18].
В случае, когда прогноз хорошо подготовлен, для его разработки подключены компетентные специалисты, когда используется достоверная информация, когда оценка получена и обработана корректно, когда используются современные технологии, только тогда качественный экспертный прогноз может быть разработан [19, 20, 76, 82, 84, 85, 98, 100].
На текущий момент насчитывают несколько сотен методов прогнозирования.
Преимущества и недостатки наиболее распространенных методов, которые используются для прогнозирования количественных показателей сложных систем, представлены таблицей 1.1 [25, 56]:Таблица 1.1
Методы, используемые для прогнозирования количественных показателей сложных систем
| Метод | Преимущества | Недостатки |
| Экспоненциальное сглаживание | Простота. Единообразие их анализа и проектирования. Ясность и простота математической формулировки. Объем данных не значим. Постоянный пересмотр прогнозных значений по мере поступления фактических. | Отсутствие гибкости. Требуют весьма тонкой настройки сглаживающих функций, даже для стационарных процессов. Оптимальный выбор этих функций является отдельной достаточно сложной задачей. |
| Регрессионные методы | Простота. Единообразие их анализа и проектирования. Быстрое получение результата. | Сложность определения вида функциональной зависимости. Низкая адаптивность линейных моделей и отсутствие способности моделирования нелинейных процессов. |
| Авторегрессионные методы | Простота. Единообразие их анализа и проектирования. | Низкие адаптационные свойства. Большое число параметров модели, идентификация которых неоднозначна и ресурсоемка. Линейность и отсутствие способности моделирования нелинейных процессов. |
| Нейросетевые методы | Способность устанавливать нелинейные зависимости. Высокие адаптационные свойства. Масштабируемость. | Отсутствие гибкости. Сложность выбора архитектуры. Высокие требования к непротиворечивости обучающей выборки и ресурсоемкость процесса обучения. Невозможность интерпретации модели в терминах предметной области. Неясность в выборе числа слоев и элементов в слое. Невозможность добавления нейронов в процессе самообучения нейросети. |
Продолжение таблицы 1.1
| Экспертный подход | Возможность прогнозирования в условиях наличия неопределенности в исходной информации. Возможность причинного анализа. | Субъективное мнение отдельного эксперта или небольшой группы может оказать доминантное влияние на общее мнение и привести к неправильному прогнозу. Отрицательное влияние на решения членов экспертной группы в отдельных случаях может оказать не глубина доводов, а количество замечаний «за» и «против». |
| Прогнозирование по аналогии | Лингвистическая простота реализации. | Вероятность возникновения ситуации, когда отсутствует аналог. Резкое ухудшение результатов в случае наличия нелинейности. |
| Комбинированные методы | Определяются методами, входящими в состав комбинированной системы. | |
Обоснованность прогноза в большей мере зависит от выбора метода прогнозирования, в результате которого он был получен. Фактографические методы показывают более высокую точность, чем экспертные, так как основываются на математическом инструментарии, но значительно уступают вторым при наличии неопределенности в исходной информации.
Необходимо учесть, что из-за значительной сложности реальных систем зачастую или невозможно учесть влияние многих факторов, или невозможно получить точные результаты измерений, то есть в полученных результатах присутствует определенная степень неопределенности. В данных условиях эффективное применение показывает аппарат теории нечетких множеств [120, 121, 135, 139].
Рассмотрим основные определения нечеткой логики принятия решений, разработанной Л. Заде [63, 64, 134, 147, 183, 184, 202, 203, 211, 212].
Функция принадлежности является характеристикой нечеткого множества. Степень принадлежности к нечеткому множеству C обозначим через MFc (x), которая представляет собой обобщение понятия характеристической функции обычного множества. Исходя из этого, нечетким множеством С называется
множество упорядоченных пар вида C={MFc (x)/x}, MFc(x) [0,1]. Значение MFc (x)=0 означает отсутствие принадлежности к множеству, 1 - полную
принадлежность.
Для нечетких множеств, как и для обычных, определены основные логические операции, представленные на рисунке 1.1, из которых важное для расчетов значение имеют пересечение и объединение.
Пересечение двух нечетких множеств (нечеткое "И"): A B: MFab (x)=min(MFA (x),MFb (x)).
Объединение двух нечетких множеств (нечеткое "ИЛИ"): A B: MFab (x)=max(MFA (x), MFb (x)).
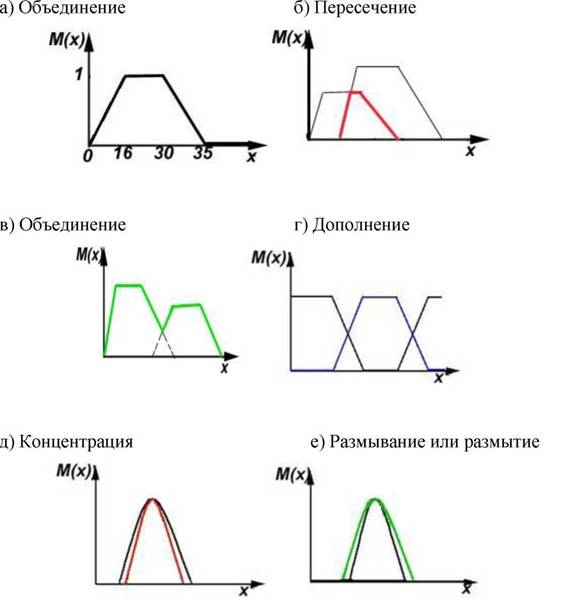
Рисунок 1.1 - Основные операции с нечеткими множествами
В теории нечетких множеств разработан общий подход к выполнению операторов пересечения, объединения и дополнения, который реализован в треугольных нормах и конормах. Такие понятия, как нечеткая и лингвистическая переменная используют для описания нечетких множеств [21, 22, 23, 26, 27, 28].
Нечеткая переменная описывается набором (N,X,A), где N - это название переменной, X - универсальное множество (область рассуждений), A - нечеткое множество на X.
Значениями лингвистической переменной могут быть нечеткие переменные, т.е. лингвистическая переменная находится на более высоком уровне, чем нечеткая переменная. Составляющие лингвистической переменной:
-•названия;
-•множества своих значений, которое также называется базовым терм- множеством T. Элементы базового терма-множества представляют собой названия нечетких переменных;
-•универсального множества X;
-•синтаксического правила G, по которому генерируются новые термы с применением слов естественного или формального языка;
-•семантического правила P, которое каждому значению лингвистической переменной ставит в соответствие нечеткое подмножество множества X.
Существует свыше десятка типовых форм кривых для задания функций принадлежности. Наибольшее распространение получили: треугольная, трапецеидальная и гауссова функции принадлежности. 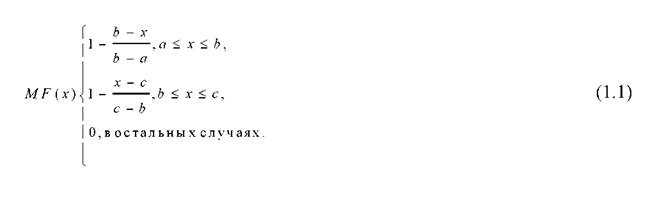
Треугольная функция принадлежности (рисунок 1.2) определяется тройкой чисел (a, b, c), и ее значение в точке x вычисляется согласно выражению:
При (b-a)=(c-b) имеем случай симметричной треугольной функции принадлежности, которая может быть однозначно задана двумя параметрами из тройки (a, b, c).
Аналогично для задания трапецеидальной функции принадлежности необходима четверка чисел (a, b, c, d):

При (b-a)=(d-c) трапецеидальная функция принадлежности принимает симметричный вид.
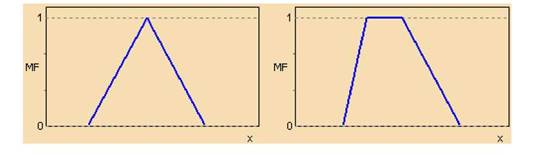
Рисунок 1.2 - Типовые кусочно-линейные функции принадлежности
Функция принадлежности гауссова типа (рисунок 1.3) описывается формулой:
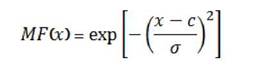
и оперирует двумя параметрами. Параметр cобозначает центр нечеткого множества, а параметр σ отвечает за крутизну функции
27
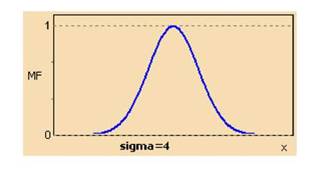
Рисунок 1.3 - Гауссова функция принадлежности
Основой для проведения операции нечеткого логического вывода является база правил, содержащая нечеткие высказывания в форме «Если-то» и функции принадлежности для соответствующих лингвистических термов. При этом должны соблюдаться следующие условия:
1. Наличие хотя бы одного правила для каждого лингвистического терма выходной переменной.
2. Для любого терма входной переменной имеется хотя бы одно правило, в котором этот терм используется в качестве предпосылки (левая часть правила).
В противном случае имеет место неполная база нечетких правил.
Пусть в базе правил имеется m правил вида:
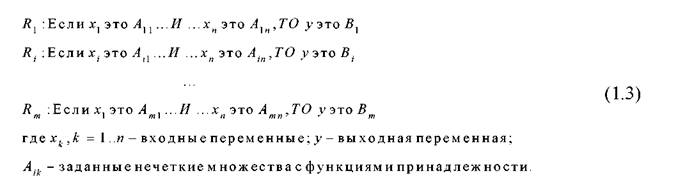
В результате нечеткого вывода получаем четкое значение переменной у * на основе заданных четких значений
xk, к = 1 ..n.
Механизм логического вывода обычно состоит из четырех этапов: (рисунок
1.4): введение нечеткости (фазификация), нечеткий вывод, композиция и приведение к четкости, или дефазификация.
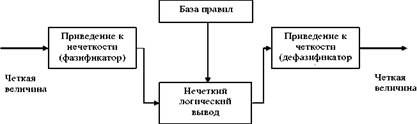
Рисунок 1.4 - Система нечеткого логического вывода
Алгоритмы нечеткого вывода в целом похожи между собой, но главным отличием являются: вид, используемых правил, логические операции и разновидность метода дефазификации. Разработаны модели нечеткого вывода Мамдани, Сугено, Ларсена, Цукамото [114, 129, 134, 147, 183, 184, 202, 203].
Нечеткие нейронные сети. Такие сети осуществляют выводы на основе аппарата нечеткой логики, однако параметры функций принадлежности настраиваются с использованием алгоритмов обучения нейронных сетей. Поэтому для подбора параметров таких сетей применим метод обратного распространения ошибки, изначально предложенный для обучения многослойного персептрона. Для этого модуль нечеткого управления представляется в форме многослойной сети. Нечеткая нейронная сеть, как правило, состоит из четырех слоев: слоя фазификации входных переменных, слоя агрегирования значений активации условия, слоя агрегирования нечетких правил и выходного слоя [140].
Адаптивные нечеткие системы. Среди классических нечетких систем выделяют следующий недостаток: для формулирования правил и функций принадлежности необходимо привлекать экспертов из предметной области, что не всегда является удобным. Адаптивные нечеткие системы с этой проблемой справляются в полной мере. Для таких систем присуще подбирать параметры
нечеткой системы и производить в процессе обучения на экспериментальных данных. Алгоритмы таких систем состоят из двух стадий:
1. Генерация лингвистических правил;
2. Корректировка функций принадлежности.
Первую задачу относят к задаче переборного типа, вторую - к оптимизации в непрерывных пространствах. При этом возникает определенное противоречие: для генерации нечетких правил необходимы функции принадлежности, а для проведения нечеткого вывода - правила. Кроме того, при автоматической генерации нечетких правил необходимо обеспечить их полноту и непротиворечивость [29, 49, 54, 59, 96, 138, 142]. Значительная часть методов обучения нечетких систем использует генетические алгоритмы.
Нечеткие запросы. Нечеткие запросы к базам данных - перспективное направление в современных системах обработки информации. Данный инструмент дает возможность формулировать запросы на естественном языке. Для этой цели разработана нечеткая реляционная алгебра и специальные расширения языков SQL для нечетких запросов.
Нечеткие ассоциативные правила. Нечеткие ассоциативные правила - инструмент для извлечения из баз данных закономерностей, которые формулируются в виде лингвистических высказываний. Здесь введены специальные понятия нечеткой транзакции, поддержки и достоверности нечеткого ассоциативного правила.
Нечеткие когнитивные карты. Нечеткие когнитивные карты были предложены Б. Коско в 1986 г. и используются для моделирования причинных взаимосвязей, выявленных между концептами некоторой области. В отличие от простых когнитивных карт, нечеткие когнитивные карты представляют собой нечеткий ориентированный граф, узлы которого являются нечеткими множествами. Направленные ребра графа не только отражают причинноследственные связи между концептами, но и определяют степень влияния (вес) связываемых концептов. Активное использование нечетких когнитивных карт в качестве средства моделирования систем обусловлено возможностью наглядного
представления анализируемой системы и легкостью интерпретации причинно - следственных связей между концептами. Основные проблемы связаны с процессом построения когнитивной карты, который не поддается формализации. Кроме того, необходимо доказать, что построенная когнитивная карта адекватна реальной моделируемой системе. Для решения данных проблем разработаны алгоритмы автоматического построения когнитивных карт на основе выборки данных.
Нечеткая кластеризация. Нечеткие методы кластеризации, в отличие от четких методов (например, нейронные сети Кохонена), позволяют одному и тому же объекту принадлежать одновременно нескольким кластерам, но с различной степенью. Нечеткая кластеризация во многих ситуациях более "естественна", чем четкая, например, для объектов, расположенных на границе кластеров. Наиболее распространены: алгоритм нечеткой самоорганизации c-means и его обобщение в виде алгоритма Густафсона-Кесселя.
Также существуют объединения, такие как нечеткие деревья решений, нечеткие сети Петри, нечеткая ассоциативная память, нечеткие самоорганизующиеся карты и другие гибридные методы.
В настоящее время в различной литературе описано достаточно много методов нечеткого прогнозирования, среди которых наиболее часто ссылаются на [147]: методы нечеткого регрессионного анализа; методы нечеткого
авторегрессионного анализа; методы нечеткого нейросетевого анализа; методы анализа нечетких тенденций.
В классическом нечетком прогнозировании прогноз строится в виде нечеткого числа, а нечеткие прогнозы делятся на две группы [147].
1) индивидуальные (прогнозы отдельных экспертов);
2) коллективные (прогнозы группы экспертов).
Отметим, что индивидуальные прогнозы относятся к классу L-R нечетких чисел, а коллективные, в общем случае, могут и выходить за пределы этого класса нечетких чисел.
В случае коллективных нечетких прогнозов выделяется 3 схемы их выработки:
1) жесткие (прогнозы строятся группой экспертов);
2) мягкие (экспертами строятся индивидуальные прогнозы);
3) комбинированные (комбинации первых двух схем).
Применение этих схем выработки прогнозов соответственно приводит к жестким, мягким и комбинированным нечетким прогнозам.
Жесткий нечеткий прогноз - нечеткое число, полученное в результате реализации определенной процедуры многотуровой групповой экспертизы.
Мягкий нечеткий прогноз - нечеткое число, полученное на основе агрегирования индивидуальных нечетких прогнозов.
Комбинированный нечеткий прогноз - нечеткое число, полученное в результате агрегирования жесткого нечеткого прогноза определенной подгруппы экспертов и индивидуальных нечетких прогнозов экспертов, не вошедших в эту подгруппу.
Природа нечетких временных рядов обусловлена использованием экспертных оценок, присущая неопределенность которых относится к классу нечеткости [124, 130, 133]. В отличие от стохастической неопределенности нечеткость затрудняет или даже исключает применение статистических методов и моделей, но может быть использована для принятия предметно-ориентированных решений на основе приближенных рассуждений человека. Формализация интеллектуальных операций, моделирующих нечеткие высказывания человека о состоянии и поведении сложных явлений, образует сегодня самостоятельное направление научно-прикладных исследований, получившее название «нечеткое моделирование». Указанное направление включает комплекс задач, методология решения которых опирается на теорию нечетких множеств, нечеткой логики, нечетких моделей (систем) и гранулярных вычислений.
При прогнозировании временного ряда (BP) неопределенность поведения моделируется в рамках стохастических моделей на основе представления BP, как реализации случайного процесса. Однако неопределенность поведения в
организационно-технических системах не всегда может быть адекватно смоделирована методами теории случайности, если:
1. Неизвестны вероятностные характеристики стохастического процесса, генерирующего BP;
2. Имеется неопределенность и неполнота в исходной информации о функционировании системы;
3. Нелинейный характер искомой зависимости;
4. Малое количество наблюдений.
В этом случае находят применение интеллектуальные методы анализа ВР, активно использующие знания экспертов.
На рисунке 1.5 приведен абстрактный пример формирования нечеткого ВР.
Прикладной аспект проблематики анализа нечетких ВР определяется возможностью расширения множества задач обработки ВР, множества технологий их решения за счет оперирования не только количественной, но и качественной информацией [45, 89, 119, 143, 148, 150, 152, 159].
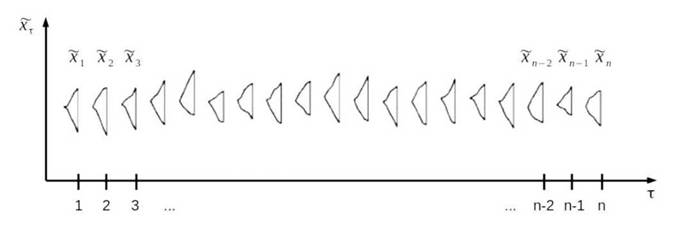
Рисунок 1.5 - Абстрактный нечеткий временной ряд
Анализ эффективности решения задач прогнозирования аналогичных по своей постановке и ситуации данных задачам, решаемым в данной работе, показал, что адекватных результатов, приемлемых для медицинской практики удается достичь при использовании методологии синтеза гибридных нечетких
решающих правил, разработанной на кафедре биомедицинской инженерии ЮгоЗападного государственного университета [72, 74, 80, 86, 88, 90, 91]. В соответствии с этой методологией задача прогнозирования рассматривается как нечеткая задача классификации, в соответствии с которой строят математические модели, определяющие уверенность в переходе обследуемого в исследуемый прогнозируемый класс состояний [13, 16, 32, 33, 34, 46, 118, 173, 204].
1.3
Еще по теме Методы и модели четкого и нечеткого прогнозирования:
- 2.2. Метод синтеза нечетких математических моделей прогнозирования и ранней диагностики профессиональных заболеваний работников электроэнергетики.
- 2 метод и модель нечеткого прогнозирования и ранней диагностики профессиональных заболеваний работников агропромышленного комплекса, контактирующих с ядохимикатами
- Разработка метода построения гибридных нечетких моделей для прогнозирования возникновения и осложнений артериальной гипертензии у водителей транспортных средств с учетом энергетических характеристик биоактивных точек
- Синтез гибридных нечетких моделей прогнозирования возникновения и рецидивов гангрены нижних конечностей
- Метод синтеза гибридных нечетких решающих правил прогнозирования возникновения и развития гангрены нижних конечностей
- 1.3. Методы распознавания образов и нечеткая логика в задачах прогнозирования и медицинской диагностики
- Обзор математических методов прогнозирования, особенности использования нечеткой логики принятия решений при мочекаменной болезни
- 2.2. Метод синтеза нечетких решающих правил прогнозирования и ранней диагностики работников агропромышленного комплекса, контактирующих с ядохимикатами.
- 3 Методы и модели структурно - функциональных решений при прогнозировании ишемических рисков
- 2.4 Метод синтеза гетерогенных математических моделей прогнозирования повторного инфаркта миокарда в реабилитационном периоде
- Синтез нечетких решающих правил прогнозирования и ранней диагностики заболеваний нервной системы.
- Нечеткие модели принятия решений в медицинских диагностических системах