ЭТАП 13. ОЦЕНКА ИНФОРМАТИВНОСТИ ГРАДАЦИЙ, ПРИЗНАКОВ И НАБОРОВ ПРИЗНАКОВ (ТАБЛИЦ РАСПОЗНАВАНИЯ). ОБЩИЙ ПОРЯДОК ВЫЧИСЛЕНИЙ ДБ И R
Информатика рассматривает процессы, происходящие в биологических системах, в системах обслуживания, в производстве и, соответственно, их модели как процессы переработки информации, изучает количественные закономерности информационных процессов.
Поэтому так называемые меры информации в статистикепредставляют особый интерес. Не рассматривая общие принципы теории информации, отметим лишь, что под количеством информации можно понимать величину устраненной неопределенности. Теория информации рассматривает меры неопределенности или неупорядоченности (энтропии) и упорядоченности (негэнтропии). Для измерения количества информации Н. Винер и К. Шеннон независимо друг от друга в 1948 г. предложили логарифмические меры, получившие признание в качестве количественных мер информации [183]. К классу подобных логарифмических мер относится введенная Jeffreus в 1946 г. и подробно изученная в качестве информационной меры Кульбаком [183] мера J1>2 дивергенции статистических распределений 1 и 2. Для дискретных распределений эта мера выражается формулой Кульбака

Информативность набора признаков (таблицы распознавания, решающего правила), построенного на основе ПА, равна сумме информативностей входящих в набор признаков:

Это — для «среднего» пациента. Если бы все были «средними», то мы, оценив полученную величину по таблице приложения 5, могли бы сказать, во сколько раз правильные ответы будут встречаться чаще, чем ошибочные. У реальных пациентов будет наблюдаться разброс достигнутых значений сумм патов и, грубо говоря, половина из них наберет больше средней, а вторая половина — меньше, т. е. не достигнет средней суммы.
Рис. 10.1. Распределение температуры тела при нереанимационной А і (кружки и пунктир) и реанимационной А2 (точки и сплошная линия) степенях тяжести угрожающего состояния.
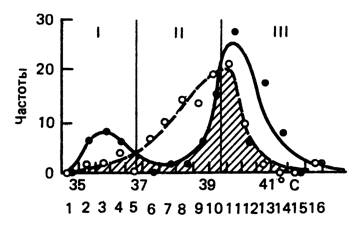
Хорошо видны зоны преобладания частоты Л2 (IX Ах (II) и снова А2 (III).

Пример расчетов по формулам (10.11) и (10.12) для случая равных априорных вероятностей состояний А1 и Л2 дается в разделе 10.7.
10.6.2. Общий порядок вычисления ДБ и R для двух независимых распределений численного признака. Практический порядок вычислений при разработке диагностической таблицы представлен в табл. 10.1 на примере признака «температура тела» (рис. 10.1).
После разбиения признака на диапазоны, число которых обычно колеблется от 8 до 16, если это количественный признак, следующим этапом является подсчет числа наблюдений в каждом диапазоне при каждом из заболеваний и Л2 (столбцы 3 и 4 табл. 10.1). Далее, определив суммарное число наблюдений при каждом из состояний Ах и А2 (их = 60, п2 = 87), принимаем каждое из них за 100% и вычисляем частоты Р(ху/Ах) и Р(ху/А2) в каждом диапазоне (столбцы 5 и 6). Затем вычисляем отношения частот (столбец 8) и ДБ (паты). Для определения ДБ (столбец 9) можно воспользоваться приложением 5. Для уменьшения влияния случайных флюктуаций в распределениях производится замена ДБ, равных нулю или бесконечности, величинами ДБ с абсолютным значением от 3 до 9 (столбец 10) по правилу, представленному в подразделе 9.5.1, стр. 70. Это уменьшает влияющие на ДБ случайные флюктуации распределений. Другие способы уменьшения случайных флюктуаций рассмотрены в разделе 9.5.
Следующим этапом является объединение диапазонов «на глаз» (столбец 11) и по базовым границам, проводимым «под» максимальными модулями (абсолютными значениями) разностей накопленных частот (столбец 16).
Техника вычислений ДБ в укрупненных диапазонах состоит в следующем. После выбора границ объединенных диапазонов суммируют частоты наблюдений в пределах этих границ для группы А2 (столбец 5 табл. 10.1) и для группы Аг (столбец 6). Затем вычисляют отношения объединенных частот и их десятичные логарифмы, умноженные на 5, т.
е. объединенные ДБ. Рассмотрим этот расчет для диапазонов 1, 2 и 3.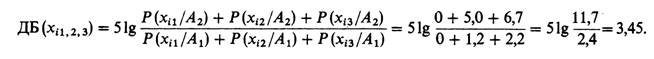
Последовательность вычисления данных для диагностической таблицы на примере признака «Температура тела»
Частоты даны в процентах
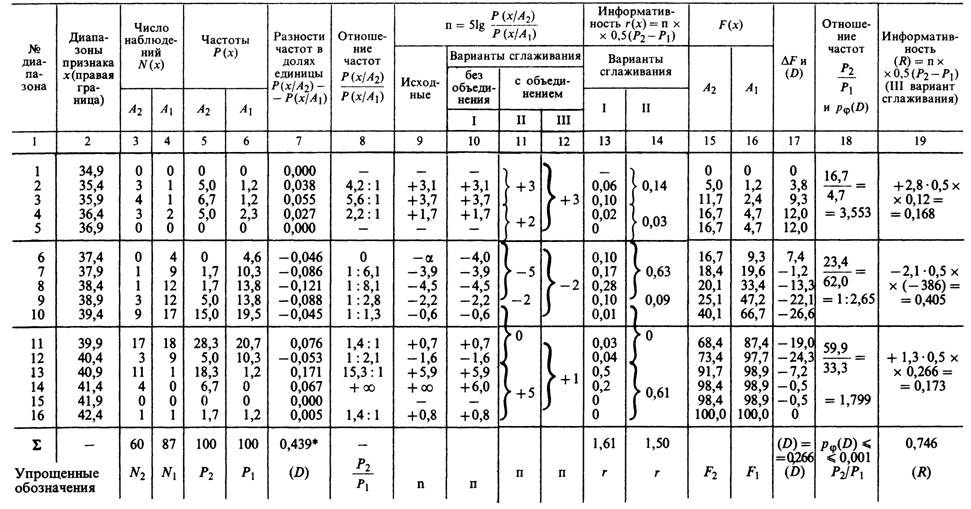
* Сумма абсолютных значений, деленная на 2. Она равна сумме положительных разностей, которая, в свою очередь, равна сумме отрицательных разностей. Это — величина D(xJ, вычисленная простейшим способом (см. подраздел 9.3.2). В данном случае она на 0,439 — 0,266 = 0,173 больше, чем />Ц), вычисленная ^4 по максимальной разности накопленных частот (столбец 17).
Полученную величину округляем с точностью до единицы. Получаем +3.
Объединение диапазонов является одним из способов уменьшения влияния случайных флюктуаций в распределениях на диагностическую таблицу (наряду с другими способами, рассмотренными в разделе 9.5).
Следующим этапом является вычисление информативности признака. В столбцах 13,14 и 19 представлена информативность диапазонов, вычисленная по формуле (10.11) для случая Р(А^ = Р(Л2) = 0,5. Например, для 2-го диапазона:
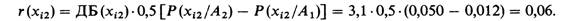
Практически при этом используется вычисленная ранее величина ДБ, равная для 2-го диапазона 3,1. Частоты при вычислениях должны быть представлены в долях единицы, а не в процентах.
Информативность в объединенных диапазонах вычисляется аналогичным способом. Величины Pfrij/AJ и Р(хц!А2) в формуле (10.11) получают суммированием соответствующих частот в объединенных диапазонах.
Информативность признака в целом получают по формуле (10.12). Например, в столбце 12 она равна:
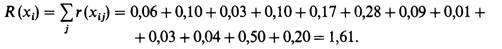
Следует отметить, что при объединении диапазонов «на глаз» (столбец 11) до оптимального их укрупнения по разработанному позже методу (по методике критерия X) одна из границ будущего оптимального базового диапазона оказалась внутри 5-го диапазона, выделенного «на глаз», что и клинически не выглядит удачным. При первом делении, видимо, ввел в заблуждение исходный диапазон № 12 (температура 40...40,4 °С), который, вероятно чисто случайно, оказался более характерным для менее тяжелого УС.
10.7.