Выбор архитектуры вычислительной системы
Разнообразные архитектуры вычислительных систем являться основой формирования концепций интеллектуального анализа. К примеру, подобные, равно как многопроцессорные вычислительные системы, облачные вычисления в сети ин
тернет, кластеры и грид-приложения.
Το что затрагивает особенности решаемой проблемы, в таком случае к вычислительной системе следует использовать соответствующее условия:1. Невысокая цена окончательного продукта. Значительная доля медицинских учреждений обладает небольшим госбюджет в формирование ИТ-инфраструктуры.
2. Вероятность существенного географического удаления друг с друга ресурсов - баз данных.
3. Обеспечение значительной безопасности данных с взлома каналов и узлов передачи информации, для того чтобы не допустить оглашение врачебной тайны.
4. Обеспечение обработки больших объемов различных сведений.
5. Обеспечение способности масштабирования концепции, в случае если произойдет увеличение медицинского института, или существенно возрастет количество источников информации, применяемых с целью рассмотрения.
Далее пересмотрены виды имеющихся архитектур вычислительных систем, какие отвечают сформулированным больше условиям.
Мультисистемные вычисления очень дороги. Однако вся вычислительная инфраструктура может быть собрана и установлена в одном месте. Это повышает безопасность обрабатываемых данных с точки зрения информационной безопасности. Вторым существенным недостатком является сложность будущей шкалы системы [142].
Кластер состоит из независимых вычислительных систем, подключенных к сети, и управляется через одну систему. Наличие, высокая эффективность, высокая энергия, и баланс нагрузки есть положительные аспекты пользы архитектуры кластера. Однако существует ряд недостатков, которые могут заключаться в том, что ресурсы медицинских учреждений находятся далеко друг от друга и не могут быть связаны с единой сетью данных.
Кроме того, из-за использования закрытых устройств взаимодействия между узлами сети теряется возможность мобильной передачи такой системы. Для реализации интернет-вычислений необходимо установить специальное ПО на компьютеры, участвующие в вычислениях, которые используют небольшую часть ресурсов компьютера пользователя для решения небольшой части общей задачи. Такой подход позволяет использовать огромные географические ресурсы для решения проблем. С другой стороны, есть проблема с интернет-безопасностью.
Идея веб-приложений заключается в том, что ресурсы распределены географически и находятся в сети, которую можно считать мощным суперкомпьютером. Специфика веб-приложений заключается в том, что они не имеют централизованного управления, поскольку каждый ресурс принадлежит определенному владельцу [144]. Тем не менее, преимущества этой архитектуры могут быть выделены. Вот основные моменты:
1. Децентрализованное управление. Внедрение веб-приложений, децентрализация управления ресурсами. Это позволяет использовать различные политики управления.
2. Это дает возможность практически безграничного масштаба сетевого приложения за счет добавления новых ресурсов и возможностей.
3. Открытая технология.
После анализа архитектуры установлено, что сетевая система в значительной степени отвечает требованиям программ интеллектуального анализа данных. Архитектура сетки DataMining (DMGA) является наиболее распространенной [145].
Усовершенствованная система комплексного интеллектуального анализа медицинских данных должна способствовать интеграции не только в другие медицинские информационные системы, но и в системах поддержки принятия решений в медицинских учреждениях.
На рисунке 1.6 рассмотрено взаимодействие разрабатываемой системы комплексной интеллектуальной обработки медицинских данных с другими элемен-
тами информационной инфраструктуры медицинского учреждения. На схеме также представлены основные хранилища, каналы передачи данных, а также блоки обработки.
Взаимодействие элементов системы: врач-диагност записывает информацию о пациентах, в том числе истории болезней, которые хранятся в МИС в формате электронных медицинских записей. Следом происходит перемещение структурированных данных из электронных медицинских записей в область хранения структурированных данных. Вся текстовая информация из электронных медицинских записей в первую очередь записывается в область неструктурированных данных. Затем блок анализа неструктурированных данных обрабатывает эту информацию, делает ее структурированной и записывает в хранилище структурированных данных. И последним этапом является анализ блоком комплексного анализа структурированных данные и перемещение их в хранилище.
38
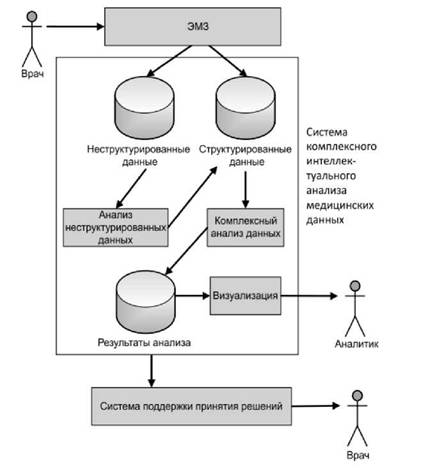
Рисунок 1.6 Система комплексного интеллектуального анализа данных в информационной инфраструктуре медицинского учреждения.
Терапевт имеет возможность отображать данные из базы данных. Он также может быть обновлен в базе данных медицинской поддержки. Таким образом, как указано выше, архитектура сети DataMining отвечает требованиям архитектуры системы комплексного интеллектуального анализа медицинских данных до максимума. Архитектура интеллектуального анализа данных сеточная архитектура на основе системы сетевых спецификаций архитектуры открытых сетевых служб. Согласно спецификациям архитектуры открытых сетевых сервисов, каждый компонент распределенной вычислительной системы считается сервисом. Однако различные службы, составляющие одну систему, могут запускаться владельцем
служб независимо. Открытые спецификации грид-архитектуры включают группы услуг: инфраструктура, службы управления полетами, службы данных, службы управления ресурсами, информационные службы, Службы безопасности. Взаимодействие всех этих служб осуществляется через протокол SOAP. Высокоразвитая система комплексного интеллектуального анализа медицинских данных представляет собой группу сервисов, работающих на удаленных узлах компьютерной сети.
Помимо основных сервисов, определенных стандартом οpen netwοrk Hreliiteeture, существует еще один сервис, позволяющий извлекать информацию из неразборчивых данных (рисунок 1.7).1) Служба доступа к данным используется для поиска и передачи, а также для публикации необходимых объемов данных, используемых в будущем. Эти группы находятся в неразборчивых и структурированных базах данных.
2) Сервис доступа к алгоритмам и инструментам поиска инструментов и алгоритмов, которые будут использоваться в процессе интеллектуального анализа данных. Это алгоритмы и инструменты для применения методов классификации, потоков, регрессионного анализа, автоматической генерации гипотез в созданной системе.
3) Служба управления производством поддерживает создание алгоритмов решения системных задач путем создания надлежащего плана выполнения и добавления группы ресурсных ограничений.
Для каждого случая создается персональная программа управления с помощью системы, которая написана для репозитория.
Результаты показывают службу, содержащую средства визуализации и представление информации о спасении. Он также может быть сохранен в формате, необходимом для будущего использования.
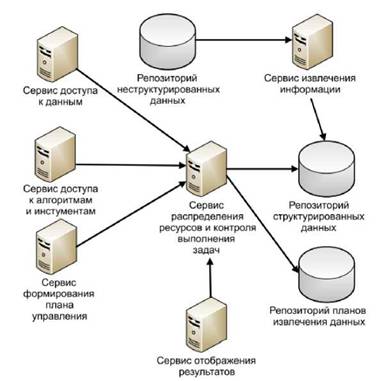
Рисунок 1.7 Архитектура системы комплексного интеллектуального анализа медицинских данных
Поиск данных основан на методах лингвистического анализа данных и предназначен для анализа данных из медицинских данных. Например, он имеет возможность извлекать из медицинской документации информацию о симптомах, диагностических процедурах, заболеваниях и медицинских вмешательствах, названии лекарств и т. д. кроме того, предлагается определить эти свойства, обнаруженные в тексте тела: эффект лечения, тяжесть и характеристика заболевания. Полученная информация будет использоваться в качестве маркеров при интеллектуальном анализе медицинской информации.
Разработка веб-приложений интеллектуального анализа осуществляется с использованием специальных программных платформ.
Наиболее распространенными являются UNICORE [149] и Gbbus Тооікії [148]. Принесите столик. 1.1 показаны их сравнительные свойства.
Таблица 1.1 Сравнительные характеристики грид-платформ
| Название платформы | Gkbus Тооікії | UNICORE |
| Лицензия | Apadie | BSD |
| Графический клиент | Сторонние разработки | Присутствует |
| Тип | Набор инструментов для создания грид- приложений интеллектуального анализа данных | Грид-платформа интеллектуального анализа данных |
| API для клиентов | SAGA | DESHL, SAGA |
| Архитектура | OGSA | OGSA |
| Протоколы передачи данных | SOAP | SOAP |
| Безопасность | X.509 (SSL) | X.509 (SSL) |
Из таблицы можно сделать вывод, что существующие платформы для создания сетевых приложений для интеллектуального анализа данных имеют аналогичные технические характеристики. Преимущества UNICORE включают в себя более бесплатную лицензию, а также тот факт, что эта платформа содержит графический клиент в списке инструментов.
Разработка систем анализа данных на естественном языке сопровождается следующими проблемами. Во-первых, необходимо предусмотреть механизмы взаимодействия гетерогенных систем для выполнения разных видов анализов
между собой. Во-вторых, такие системы требуют средств работы с большим количеством языковых ресурсов - тезисов, машин для моделирования и обучения, помеченных как Согрога. В-третьих, из-за того, что алгоритмы обработки текста требуют больших вычислительных ресурсов, для обеспечения масштабируемости таких систем необходимо обеспечить возможность их расположения в некоторых вычислительных точках.
В настоящее время специализированные платформы для анализа неструктурированной информации принимают на себя решение этих проблем. Самыми эффективными и пристроенными гонками сегодня являются платформы GATE и Apadie UIMA. В табл. 1.2 Представлены их сравнительные характеристики.Таблица 1.2 Сравнительные характеристики платформ для обработки текстов на естественном языке
| Название плат формы | GATE | Apadie' UIMA |
| Лицензия | GPL, LGPL | Apadie |
| Поддерживаемые языки программирования | Java | Java, C++ |
| Поддержка распределенных вычислений | Нет | Да |
| Графический интерфейс для разработки приложения | Да | Да (плагин Edipse) |
Продолжение таблицы 1.2
| Графический интерфейс для работы с разметкой | Да | Да (плагин Edipse) |
| Средства для тестирования качества | Да | Да |
| Средства для профилирования скорости | Нет | Да |
Главными преимуществом платформы АрасЬе UIMA над GATE является наличие средств для профилирования анализаторов, а также наличие возможности масштабирования за счет применения распределенных вычислений. Также UIMA имеет возможность интеграции в систему программных модулей, которые реализованы как на языке C++, так и на языке Java. Это позволяет создавать эффективные модули на языке С++,который ориентирован на ресурсоемкие вычисления, а также увеличивает гибкость разработки, благодаря использованию уже готовых решений из обоих языках. На основе этих преимуществ использование платформы Apaehe UIMA для разработки системы анализа медицинских показателей является более предпочтительным.
1.4